Best Practices for GDPR in Data Annotation
· Data Annotation
GDPR guidance for data annotation: minimize and anonymize data, get informed consent, enforce encryption and access controls, and run DPIAs.
Best Practices for GDPR in Data Annotation
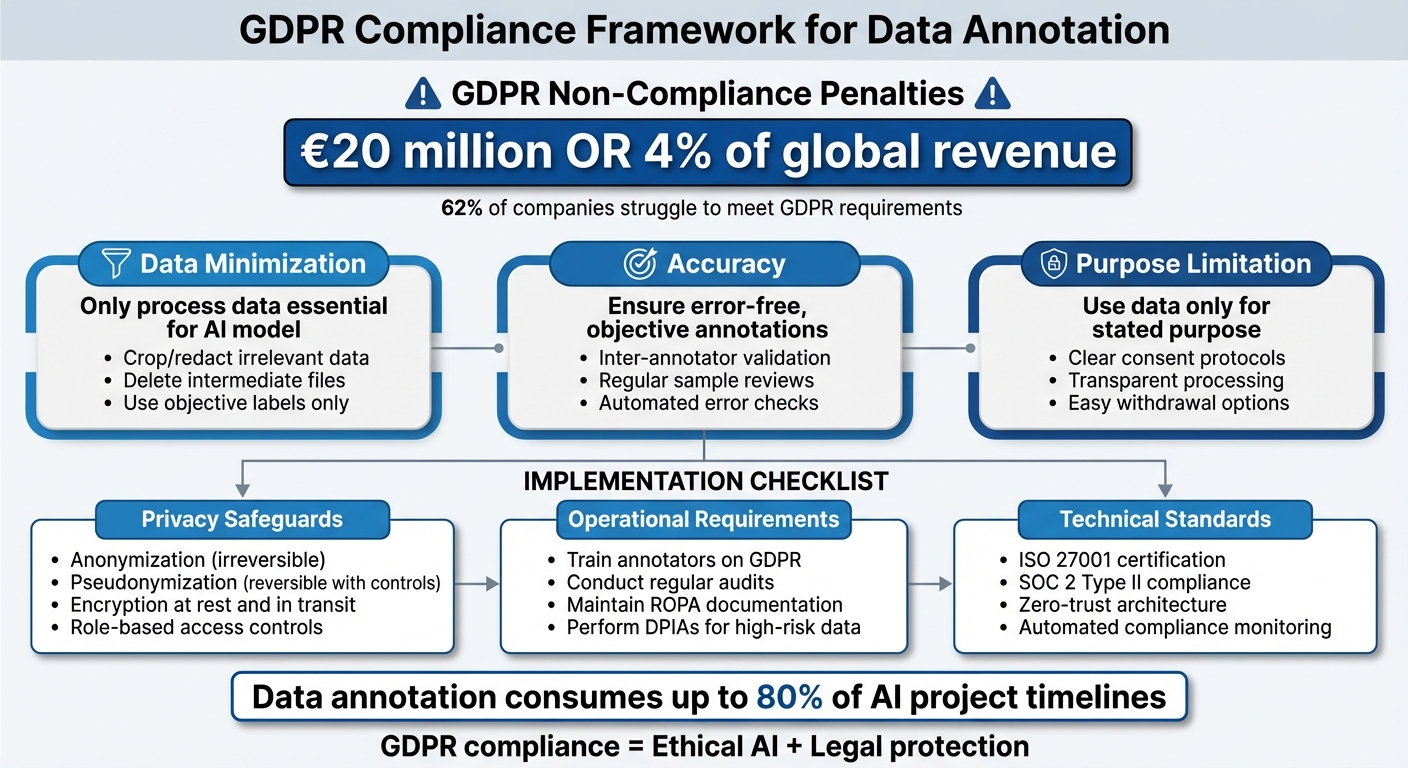
GDPR compliance in data annotation is non-negotiable. Mishandling personal data can lead to fines up to €20 million or 4% of global revenue. Here's what you need to know:
- Data Annotation = Data Processing: It involves handling personal data like names, images, and health records. This makes GDPR compliance mandatory.
- Key Principles to Follow:
- Purpose Limitation & Data Minimization: Only collect and process data essential for your AI model.
- Informed Consent: Users must clearly understand and agree to how their data will be used.
- Accuracy: Ensure annotations are error-free and regularly reviewed.
- Privacy Safeguards:
- Use anonymization (irreversible data masking) or pseudonymization (reversible masking with controls).
- Encrypt data and enforce strict access controls.
- Regularly audit and document processes to meet GDPR standards.
GDPR compliance is not just a legal requirement - it ensures ethical AI development while protecting individuals' rights. Keep reading for practical steps to secure your annotation workflows.
GDPR Compliance Framework for Data Annotation: Key Principles and Implementation Steps
AI-Powered Data Annotation - Generative AI Lab
GDPR Principles That Apply to Data Annotation
The GDPR isn't just about broad rules - it lays out specific principles that directly influence how data annotation should be managed. These principles are essential for ensuring privacy is built into your workflows from the start, rather than scrambling to fix compliance issues later. They also build on the roles of Data Controllers and Processors, providing a clear framework for handling personal data responsibly.
Purpose Limitation and Data Minimization
Under Article 5(c) of the GDPR, personal data must be "adequate, relevant and limited to what is necessary in relation to the purposes for which they are processed". This means annotators should only access the data strictly required for the AI's purpose. Including irrelevant details, like someone's profession in a presence detection model, violates the principle of data minimization. The French CNIL explains, "Information is relevant if its link to model performance is proven (theoretically, or empirically, notably in scientific publications) or sufficiently plausible".
When using pre-existing, purchased, or open-source datasets, it's important to "triage" the data - removing or ignoring annotations that aren't essential for your AI system. Techniques like cropping, redaction, or masking can help ensure only necessary data is exposed. For example, if annotators need to label street signs in images, crop out faces and license plates before the images are handed over. Similarly, delete intermediate files, such as compressed versions created for system transfers, once they are no longer needed.
| Minimization Measure | Workflow Application |
|---|---|
| Data Cropping/Redaction | Removing irrelevant parts of an image or text before it reaches the annotator |
| Label Selection | Using objective, factual labels (e.g., RGB values for skin tone) instead of subjective ones |
| Automated Data Tracing | Tracking data through its lifecycle to identify and delete unnecessary duplicates |
| Retention Schedules | Deleting outdated training data that no longer serves a predictive purpose |
The UK Information Commissioner's Office (ICO) adds, "The data minimisation principle does not mean either 'process no personal data' or 'if we process more, we're going to break the law.' The key is that you only process the personal data you need for your purpose".
In addition to minimizing data, having clear and transparent consent protocols is equally important.
Informed Consent and User Control Options
When consent serves as your legal basis for data annotation, GDPR sets strict standards. Consent must be specific, informed, and freely given. This means users need to fully understand what they are agreeing to before clicking "I accept." Your consent request must clearly outline your organization’s name, the purpose of processing, and the specific activities involved. According to the ICO, "Consent requests need to be prominent, concise, easy to understand and separate from any other information such as general terms and conditions".
Pre-ticked boxes, opt-out mechanisms, or assuming silent consent are not allowed under UK GDPR. Consent should also be granular, giving users separate opt-in options for different types of processing rather than bundling everything into one. Importantly, users must be informed of their right to withdraw consent at any time. Article 7(3) of the UK GDPR states, "The withdrawal of consent shall not affect the lawfulness of processing based on consent before its withdrawal. Prior to giving consent, the data subject shall be informed thereof. It shall be as easy to withdraw as to give consent".
For online consent, make the withdrawal process just as straightforward. Provide an online link for withdrawal instead of requiring users to call or mail a letter. User-friendly privacy dashboards or preference-management tools can help users easily access, update, or withdraw their consent settings. As the ICO warns, "If you cannot offer a genuine choice, consent is not appropriate. If you would still process the personal data without consent, asking for consent is misleading and inherently unfair".
Accuracy in Annotations
Accuracy is another cornerstone of GDPR compliance. Article 5(d) of the GDPR requires personal data to be "accurate and, where necessary, kept up to date; every reasonable step must be taken to ensure that personal data that are inaccurate... are erased or rectified without delay". For data annotation, this principle is critical because annotations serve as the "ground truth" for AI models. Mistakes in annotations can lead to AI systems learning and perpetuating errors. The French CNIL cautions, "The system could reproduce the inaccuracies of the annotation later, during the deployment of the system and lead to inaccurate, even degrading or discriminatory exits".
Inaccurate annotations also infringe on individual rights. Article 16 grants data subjects the right to rectification, meaning you must have processes in place to correct errors when requested. To maintain accuracy, establish clear annotation protocols that prioritize objective, unambiguous labels while avoiding subjective or harmful terms. Techniques like inter-annotator agreement validation - where multiple annotators label the same data to ensure consistency - can help. Additionally, regularly review random samples of annotated data and use automated checks to catch errors.
Methods for Protecting Data Privacy During Annotation
Once you’re familiar with the GDPR principles that guide your annotation workflows, the next step is putting practical safeguards in place to protect personal data. These safeguards turn GDPR guidelines into actionable steps.
Anonymization and Pseudonymization Methods
Understanding the difference between anonymization and pseudonymization is key. Pseudonymized data is still considered "personal data" since it can be re-identified using additional information, often referred to as a "key." In contrast, anonymized data is altered in a way that makes re-identification impossible, placing it outside GDPR's scope entirely. According to the Information Commissioner’s Office (ICO):
"Pseudonymisation refers to techniques that replace, remove or transform information that identifies people, and keep that information separate".
Several techniques can help protect data:
- Hashing: Converts data into fixed-length, one-way values. Strong algorithms are essential to prevent reverse-engineering.
- Tokenization: Replaces sensitive data with secure tokens.
- Encryption: Makes data unreadable unless decrypted with a key, providing an extra layer of security. GDPR Article 34 even notes that encryption can eliminate the need for breach notifications if data becomes “unintelligible to unauthorized persons”.
For full anonymization, methods like generalization (e.g., replacing a birthdate with an age range) and suppression or masking (e.g., turning "John Smith" into "XXX XXXX") can reduce data precision or obscure identifying details. Other techniques include:
- Data perturbation: Adds random changes to numerical values while retaining statistical trends.
- Synthetic data: Uses algorithms to generate artificial datasets that mimic real data without including personal identifiers.
- Differential privacy: Introduces mathematical noise to ensure that individual data points cannot be identified, a method adopted by companies like Apple and Google.
That said, anonymization has its limits. Research has shown that AI can re-identify 99.98% of individuals in an anonymized dataset using just 15 demographic attributes. A famous example from 2006 revealed how researchers de-anonymized Netflix’s dataset of 500,000 subscribers by cross-referencing movie ratings with public IMDb profiles. As TrustArc advises:
"The goal isn't to anonymize everything. It's to anonymize intelligently. Identify the data that drives value, protect what could cause harm, and continuously test your safeguards".
A practical way to evaluate your safeguards is through the "Motivated Intruder" Test, which assesses whether an outsider with access to public records could re-identify individuals in your dataset. Combining techniques - like suppressing names, generalizing ages, and perturbing salaries - can also reduce risks like "linkage attacks". Tools like K-anonymity ensure that each record is indistinguishable from at least k others. For pseudonymization, the ICO stresses that any "key" enabling re-identification must be stored separately and tightly controlled.
These techniques form the foundation for secure data handling, which we’ll explore further.
Encryption and Secure Data Handling
Encryption is a cornerstone of data protection. Using robust standards like AES or RSA for data at rest, combined with transport encryption for data in transit, ensures information remains unreadable even if intercepted. However, encryption alone isn’t enough - strong access controls are equally important.
Key security measures include:
- Network and hardware isolation: Annotation systems should operate in isolated networks with restricted installations and blocked peripheral access to prevent leaks.
- Role-Based Access Controls (RBAC): Limit data access to authorized personnel based on their role and project needs.
- Physical security: This can involve 24/7 video monitoring, biometric access controls, metal detectors, and even polarized screen filters to prevent unauthorized viewing.
A "zero-trust" architecture is another effective approach. This involves locking down devices, vetting annotators, and closely monitoring data movement. Regular penetration tests and external security audits can help identify vulnerabilities and maintain compliance. It’s worth noting that over 62% of companies report challenges in meeting regulations like GDPR and CCPA.
Additional steps to secure data include:
- Endpoint hardening: Ban personal electronics in secure zones and use polarized monitors to limit visibility to authorized annotators.
- Referential integrity: Use consistent encryption or masking algorithms across departments to keep data usable for analysis while safeguarding identities.
- Training and agreements: Ensure annotators undergo background checks, sign NDAs, and complete security training before accessing sensitive data.
- Secure communication: Use proprietary tools for data exchange rather than public platforms.
Look for annotation partners with certifications like ISO/IEC 27001 and SOC 2 Type II, which validate their operational safeguards and data integrity standards.
Managing Sensitive Data
Handling sensitive data, particularly special categories like health information, requires heightened vigilance. GDPR mandates additional protections, starting with a Data Protection Impact Assessment (DPIA) to identify risks and guide decisions around anonymization. A "limited access" model, where only a controlled group handles sensitive data, is critical.
Technical safeguards - like encryption, pseudonymization, and masking - remain essential. In secure annotation facilities, physical measures such as biometric access, 24/7 security, and banning personal electronics help prevent breaches. As stated in UK GDPR Article 5(1)(f):
"Personal data shall be processed in a manner that ensures appropriate security... including protection against unauthorised or unlawful processing and against accidental loss, destruction or damage, using appropriate technical or organisational measures".
AI introduces additional risks. Privacy attacks like model inversion or membership inference can occur if models are overfitted to training data. For instance, researchers have reconstructed face images from facial recognition systems with 95% accuracy. To mitigate these risks, developers should:
- Avoid overfitting models.
- Monitor API queries for unusual patterns.
- Log data movements and delete unnecessary intermediate files.
- Apply de-identification techniques before extracting data.
Supply chain vulnerabilities also pose a challenge. Machine learning frameworks often rely on numerous external dependencies, which can introduce risks. For example, in 2019, a vulnerability in the Python library "NumPy" allowed attackers to execute malicious code disguised as training data. As Sigma.ai puts it:
"Data security is not a compliance checklist; it's a continuous operational requirement that protects your project and IP".
sbb-itb-cdb339c
How to Implement GDPR Compliance in Data Annotation Operations
To align your data annotation processes with GDPR principles, focus on three key areas: training your team, conducting audits, and selecting the right tools.
Training Annotators on GDPR Requirements
Training annotators is essential for ensuring GDPR compliance. They need to understand guidelines, privacy protocols, and how to use tools effectively. The Information Commissioner's Office (ICO) emphasizes:
"Accountability is not a box-ticking exercise. Being responsible for compliance with the UK GDPR means that you need to be proactive and organized about your approach to data protection".
A well-structured onboarding program should cover GDPR's core principles like data minimization (only processing necessary data), accuracy (ensuring factual and objective labeling), and loyalty (avoiding language that could harm someone's reputation). For sensitive data, objective criteria - like RGB values for skin tone - can help eliminate bias.
Security practices also play a crucial role. Annotators should know why personal devices are restricted in secure areas, and role-based access controls should limit their exposure to only the data they need for their tasks.
Regular refresher courses are important to keep annotators updated on changes in processes or regulations. For projects dealing with potentially disturbing content, offering psychological support as part of training can help maintain team well-being. It's also smart to establish feedback channels for annotators to flag inappropriate labels or privacy concerns. As CNIL explains:
"An incorrect annotation or one that is based on inappropriate or arbitrary criteria will not respect the principle of accuracy".
Once training is complete, thorough documentation of compliance efforts is a must.
Regular Audits and Documentation
After training, ongoing documentation and audits help ensure GDPR compliance. Article 30 requires most organizations to maintain a Record of Processing Activities (ROPA), which details processing purposes, data categories, recipients, retention schedules, and security measures. For companies with 250 or more employees, documenting all processing activities is mandatory, while smaller organizations need to focus on sensitive or high-risk data.
Keep the ROPA updated as operations change. According to the ICO:
"Documenting your processing activities is important, not only because it is itself a legal requirement, but also because it can support good data governance and help you demonstrate your compliance with other aspects of the UK GDPR".
Regular audits are crucial to verify the effectiveness of your technical and organizational measures. Conduct information audits to understand what personal data you hold, where it’s stored, and who has access. Assign a Senior Information Risk Owner (SIRO) to oversee your data governance strategy. For high-risk projects, use Data Protection Impact Assessments (DPIAs) to document your decision-making process and risk mitigation plans.
Certifications like ISO 27001 or SOC 2 Type II provide third-party validation through periodic audits. Always document key decisions, such as why a specific anonymization method was chosen or how a new processing purpose aligns with GDPR requirements.
Choosing GDPR-Compliant Tools
The right tools can streamline compliance and reduce errors. Look for annotation platforms with zero-trust architecture that include role-based access controls, device restrictions, and limits on external file sharing. Privacy governance dashboards are particularly useful, offering real-time compliance monitoring and automating reporting tasks. Many organizations report a 60-80% reduction in manual compliance work with these tools.
Choose vendors with certifications like ISO 27001 and SOC 2 Type II, as these validate strong security practices. Tools should also support automated anonymization and pseudonymization to mask identifiable data before it reaches annotators. Features like versioning, logging, and inter-annotative agreement checks help maintain accuracy and integrity.
Physical safeguards, such as polarized monitor filters, can prevent unauthorized data visibility. Opt for platforms that handle complex ontologies and nested relationships, as these improve schema quality and reduce bias. As Sigma highlights:
"Data security is not a compliance checklist; it's a continuous operational requirement that protects your project and IP".
Some tools can even automate the maintenance of your ROPA, ensuring documentation stays current as your operations evolve. The shift towards continuous monitoring - rather than periodic audits - reflects the changing nature of GDPR compliance. Consider tools that integrate with Consent Management Platforms (CMPs) and data discovery systems to maintain visibility without manual intervention.
Summary and Key Points
In this article, we’ve delved into the principles of GDPR and practical security measures for data annotation. GDPR compliance in data annotation isn’t just a legal checkbox - it’s an ongoing responsibility that safeguards both your organization and the individuals whose data you handle. With potential fines reaching as high as €20 million or 4% of global annual turnover, and about 62% of companies struggling to meet data regulations, prioritizing compliance is essential.
At its core, GDPR compliance relies on three key principles: data minimization (only processing what’s necessary), accuracy (ensuring labels are objective and factual), and purpose limitation (using data solely for its intended purpose). These principles don’t just fulfill legal obligations - they’re also critical for building AI models that perform effectively and earn user trust. Considering that data annotation can consume up to 80% of AI project timelines, implementing privacy measures early on can save time and reduce risks.
To meet compliance requirements, your strategy should integrate both technical and organizational measures as outlined in Article 32. This includes encryption, pseudonymization, staff training, non-disclosure agreements, and well-documented protocols. Moving from crowdsourcing to secure, vetted workforces demonstrates a zero-trust approach. As CNIL points out:
"The data annotation phase is a decisive step in the development of a quality AI model, both for performance issues and for the respect of people's rights".
This secure framework requires thorough documentation and regular updates to remain effective.
Proper documentation plays a vital role in proving compliance during audits. Maintain a detailed Record of Processing Activities (ROPA), conduct regular Data Protection Impact Assessments (DPIAs), and log annotation protocols. Additionally, opt for tools that meet high security standards, such as ISO 27001 or SOC 2 Type II certifications.
Finally, ensure that data subject rights extend to annotations, not just raw data. Individuals must have the ability to access, correct, or delete labels connected to their data. By treating GDPR compliance as an ongoing process rather than a one-time task, you’ll create AI systems that are not only legally compliant but also ethically aligned.
FAQs
What’s the difference between anonymization and pseudonymization in data annotation?
Anonymization and pseudonymization are two techniques commonly used in data annotation to safeguard individual privacy. While they share the goal of protecting personal information, they differ in how they achieve it and in their treatment under GDPR.
Anonymization involves permanently removing all identifiable information from data, making it impossible to trace back to any individual, either directly or indirectly. Once data is anonymized, it is no longer considered personal data and falls outside the scope of GDPR regulations.
Pseudonymization, by contrast, replaces identifiable details with pseudonyms or tokens. This reduces the risk of direct identification but doesn’t completely eliminate it. The data can still be linked to individuals if additional information, such as a decryption key, is available. As a result, pseudonymized data remains classified as personal data under GDPR and must adhere to its requirements.
To put it simply, anonymization is a one-way process that removes data from GDPR oversight, while pseudonymization is reversible and keeps the data subject to GDPR rules.
What steps can organizations take to obtain proper consent for data annotation under GDPR?
To align with GDPR requirements, organizations need to make sure that consent is clear, informed, and freely given. This means using plain, easy-to-understand language to explain why data is being collected and what it will be used for. Consent requests should stand on their own, separate from other terms and conditions, so they’re simple to grasp.
Users must also have control over their data. This includes offering straightforward options to withdraw consent whenever they choose. On top of that, it's essential to keep detailed records of when and how consent was obtained. These records can serve as proof of compliance if ever questioned.
How can you ensure accuracy in data annotation projects?
To achieve precise data annotation, start by establishing clear and detailed guidelines for annotators. This ensures everyone is on the same page, reducing errors and maintaining consistency throughout the process. Pair this with quality control measures, such as routine reviews and audits, to identify and address mistakes early.
Incorporating iterative workflows - like refining annotations based on feedback or using programmatic labeling methods - can gradually enhance accuracy. On top of that, adhering to data privacy regulations, such as GDPR, not only safeguards user information but also bolsters the trustworthiness of your annotations.
Effective project management plays a critical role as well. Focus on solid planning, maintain open communication with stakeholders, and set achievable timelines. These steps help streamline the annotation process and lead to more reliable outcomes.