Common Support Issues with Annotation Platforms: Solutions
· Data Annotation
Annotation platform pitfalls—integration, inconsistent labels, scaling, costs, security, and QA—fixed with testing, AI-assisted workflows, CDNs, encryption, and automated QA.
Common Support Issues with Annotation Platforms: Solutions
Annotation platforms are essential for building AI models, but they come with challenges. The most common issues include:
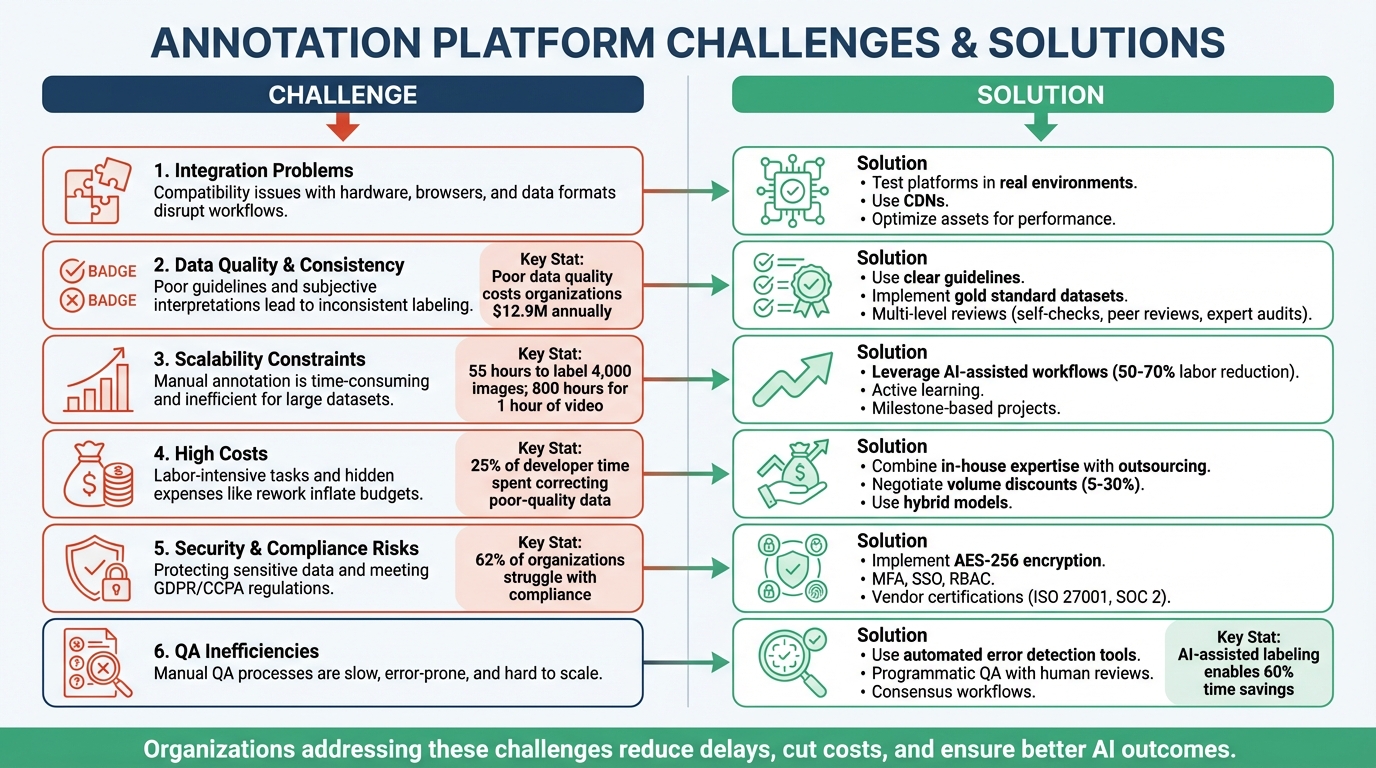
- Integration Problems: Compatibility issues with hardware, browsers, and data formats often disrupt workflows.
- Data Quality and Consistency: Poor guidelines and subjective interpretations lead to inconsistent labeling.
- Scalability Challenges: Manual annotation processes are time-consuming and inefficient for large datasets.
- High Costs: Labor-intensive tasks and hidden expenses like rework inflate budgets.
- Security and Compliance Risks: Protecting sensitive data and meeting regulations like GDPR and CCPA remain difficult.
- Quality Assurance Inefficiencies: Manual QA processes are slow, error-prone, and hard to scale.
Key Solutions:
- Integration: Test platforms in real environments, use content delivery networks (CDNs), and optimize assets for performance.
- Data Quality: Use clear guidelines, gold standard datasets, and multi-level reviews to improve consistency.
- Scalability: Leverage AI-assisted workflows, active learning, and milestone-based projects to save time and resources.
- Cost Management: Combine in-house expertise with outsourcing and negotiate volume discounts for large projects.
- Security: Implement encryption, access controls, and vendor certifications like ISO 27001 or SOC 2.
- QA Automation: Use automated tools for error detection and integrate programmatic QA with human reviews.
By addressing these challenges, organizations can reduce delays, cut costs, and ensure better outcomes for their AI initiatives.
6 Common Annotation Platform Challenges and Solutions
Integration Problems with Current Systems
Frequent Compatibility Problems
Annotation platforms often struggle to integrate smoothly with existing tech setups. For starters, hardware and browser requirements can be a major obstacle. Many platforms demand at least a 64-bit CPU, 8 GB of RAM (though 16 GB is better), and a display resolution of 1280×720 or higher. On top of that, some platforms only work with Google Chrome, leaving teams using browsers like Safari or Firefox to deal with rendering issues or broken features.
Data format mismatches are another headache. If your datasets are stored in unsupported formats, you may need to repeatedly convert files as they move between systems. Storage configuration errors can add to the frustration - 404 "Not Found" errors might pop up due to invalid file paths, incorrect bucket names, or misconfigured access keys. And if Cross-Origin Resource Sharing (CORS) isn’t enabled on your storage, browsers might download files but fail to display them properly in the annotation interface.
Network speed also plays a big role, especially for large video files or 3D point clouds. Some platforms require speeds up to 200 Mbps to avoid loading failures and laggy user interfaces . Additionally, browsers handle EXIF metadata inconsistently. Some platforms strip this data to keep labels oriented correctly, which can disrupt workflows that rely on the original metadata.
Solutions for Smooth Integration
To avoid these pitfalls, start with a trial run before committing to a platform across your entire organization. Set up a test project that mirrors your actual environment - use the same network, hardware, and peak traffic conditions to identify any latency or compatibility issues early on. If your team is spread across different regions, using a Content Delivery Network (CDN) can help speed up asset delivery and minimize lag.
For cloud storage, implement IAM delegated access to ensure security while optimizing performance. In Chrome, enabling hardware acceleration (Settings > System > "Use graphics acceleration") can improve the rendering of 3D graphics and high-resolution images. Also, consider optimizing your assets - keep images under 4000×4000 pixels and videos at 30fps or lower to prevent slowdowns in the editor. Teams that use managed cloud annotation infrastructure have reported 30–40% faster iteration cycles compared to those maintaining their own tools.
| Requirement | Minimum Threshold | Recommended for Optimal Performance |
|---|---|---|
| Memory (RAM) | 8 GB | 16 GB or greater |
| Network Speed | 40 Mbps | 200 Mbps or faster |
| Browser | Google Chrome | Latest Chrome with hardware acceleration |
| Disk Space | 4 GB available | N/A |
| Resolution | 720P (1280×720) | Higher for complex geometries |
Getting the integration right is essential for ensuring high-quality data and consistent annotations.
sbb-itb-cdb339c
Maintaining Data Quality and Annotation Consistency
Root Causes of Inconsistent Annotations
When annotation guidelines lack clarity, they leave room for subjective interpretations, which often result in inconsistent annotations. For instance, a chatbot company in 2025 managed to reduce sarcasm mislabels by 30% after revising its guidelines to include examples tied to specific cultural contexts and conducting targeted retraining sessions.
Another common issue stems from gaps in domain expertise and insufficient detail in guidelines, especially regarding edge cases like blurry images or barely visible objects. Tasks that rely on subjective judgment - such as identifying sentiment, sarcasm, or intent - are particularly prone to inconsistencies without clear consensus rules.
"AI systems are only as smart as the data they're fed - and only as trustworthy as the humans who curate it." - McKinsey Analyst
Failing to address these challenges can be expensive. Poor data quality costs organizations an average of $12.9 million annually. Additionally, about 90% of data science projects fail to move into production, with 87% of employees pointing to data quality as a major obstacle. For example, in September 2025, a global e-commerce platform refined its product categorization rules - such as determining whether "smart fridges" should be classified under electronics or appliances. This adjustment improved annotation accuracy by 22% in just one quarter.
To tackle these issues, organizations need structured quality assurance measures.
Quality Assurance Methods That Work
Effective quality assurance processes are key to resolving annotation inconsistencies. One proven approach is a three-tier review system: self-checks, peer reviews, and expert audits, which together help catch errors at multiple levels. For tasks involving subjective interpretation, consensus labeling - assigning the same task to 3–5 annotators and using majority voting or expert reconciliation - has shown success. A financial services firm applied this technique to fraud detection and reduced false positives by 18%, saving millions in operational costs.
Another strategy involves using Gold Standard datasets, which are expertly annotated benchmarks. These datasets not only measure annotator performance but also identify individuals who need additional training. A 2025 case study from an autonomous vehicle startup demonstrated the impact of this method: annotators were required to achieve at least 95% accuracy on a Gold Standard pedestrian dataset before working on production tasks, leading to a 50% reduction in error rates in live projects. Additionally, Inter-Annotator Agreement (IAA) metrics, such as Cohen's Kappa or Fleiss’ Kappa, help quantify consistency. Scores below 0.6 often signal the need for guideline revisions or retraining.
Automated QA tools can also play a vital role by identifying technical errors like overlapping bounding boxes, incorrect word counts, or annotations that fail to meet pixel thresholds - all without human intervention. Establishing a Quality Service Level Agreement (SLA) with minimum accuracy thresholds (typically 95–99%) ensures that any batch falling short of these standards is flagged for rework.
Finally, treat annotation guidelines as dynamic documents. Use version control to track updates as new edge cases arise, and store the guidelines on searchable, wiki-style platforms like Notion. This ensures annotators can easily access the latest information during active projects.
Scalability and Speed Constraints
Problems with Manual Annotation Processes
Scaling up annotation processes brings a new set of hurdles, particularly when it comes to time and resource management. Manual labeling, while effective for smaller datasets, quickly becomes a bottleneck as datasets grow into the thousands.
For instance, a single annotator requires around 55 hours to label 4,000 images. Now, imagine the challenge with video data - annotating just one hour of footage can demand up to 800 hours of human effort. These time requirements make it nearly impossible to keep up with the fast-paced demands of modern AI projects.
Adding more annotators might seem like a simple solution, but it introduces its own complications. Many open-source or in-house tools struggle to handle the complexities of large-scale data annotation, especially for advanced tasks like video or 3D point cloud labeling. Distributed teams and shifting project requirements can further impact accuracy, and attempting to label massive datasets all at once - using a “waterfall” approach - can lead to inefficiencies when priorities change mid-project.
These challenges highlight the importance of embracing scalable, tech-driven solutions to meet the growing needs of AI development.
Technology-Based Solutions
Technology offers a way to streamline and scale annotation efforts. AI-assisted workflows, for example, can significantly reduce the time and cost involved. Pre-labeling, where machine learning models generate preliminary labels for human review, slashes labor hours by 50–70%, cuts costs by 30–60%, and speeds up the process by 3 to 10 times.
Another effective approach is active learning, which directs only the most uncertain or complex cases to human annotators while automating simpler tasks. This ensures that human expertise is applied strategically, focusing on the data that matters most.
Consider this real-world example: In early 2024, CloudFactory helped a client label 1,200 hours of data in just five weeks using their managed workforce and Accelerated Annotation platform. This efficiency allowed the client to meet their product launch deadline.
| Approach | Speed Impact | Cost Impact | Best Use Case |
|---|---|---|---|
| Manual Labeling | Slow (weeks/months for large sets) | High (direct labor costs) | Small, highly nuanced datasets |
| AI-Assisted Labeling | 3x to 10x faster | 30–60% reduction | Large-scale production datasets |
| Active Learning | Focuses on high-impact data | Maximizes ROI per annotation hour | Datasets with mixed complexity |
Breaking large projects into smaller, milestone-based batches is another effective strategy. This allows teams to test models, refine guidelines, and adjust priorities between phases. Starting with a calibration phase - using a small subset of data - can help train the team and identify edge cases before scaling up to full production. Additionally, for distributed teams, using a Content Delivery Network (CDN) can reduce latency in asset delivery. Revisiting asset limits and optimizing CDN usage can further improve speed.
Managing Annotation Project Costs
Where Costs Add Up
Annotation projects often face budget challenges, primarily due to labor expenses. Tasks requiring specialized skills, such as annotating medical images from CT or MRI scans, can be 3 to 5 times more expensive than general image labeling. This is because they demand professionals with clinical expertise.
The complexity of the task also plays a significant role in cost variation. Simple annotations, like bounding boxes, can range from $0.03 to $1.00 per label, while more intricate tasks, such as 3D annotations, may cost anywhere from $0.05 to $5.00 per label. When scaling up to thousands or even millions of data points, these differences can quickly escalate into substantial expenses.
Hidden costs further complicate budgeting. For instance, 25% of developer time is spent correcting poor-quality data, and management overhead can add another 20% to 30% to the total budget. If a data scientist earning $150,000 annually is tasked with labeling, the hourly cost exceeds $70 - and jumps to $100 when benefits are factored in. In contrast, outsourcing the same work to vendors typically costs between $10 and $20 per hour.
"The real cost of annotation isn't just what you pay your vendor - it's what you pay in engineering time, project delays, model performance, and customer satisfaction." - Kognic
Identifying these cost drivers is the first step toward more efficient spending.
Ways to Reduce Costs
To manage annotation costs effectively, it’s essential to think beyond the price per label and focus on the total cost of ownership. A vendor offering low rates might seem appealing, but if your team spends extensive time fixing errors, the overall expense can skyrocket.
One approach is to adopt a hybrid model: outsource large-scale tasks while keeping complex or critical work in-house for your internal experts to handle. Leveraging AI-assisted workflows, such as pre-labeling with machine learning, can also significantly reduce the manual workload.
Start with simple annotations and only increase complexity when absolutely necessary. Before committing to large-scale contracts, run a pilot project with 1,000–5,000 annotations to assess the vendor’s quality. For projects involving over 100,000 items, negotiate volume discounts - many vendors offer reductions between 5% and 30% for high-volume work.
"Every minute a $150,000-a-year data scientist spends drawing bounding boxes... is time they could use to improve your model." - NeoWork
Data Security and Regulatory Compliance
Common Security and Compliance Problems
Beyond challenges like integration hurdles and rising expenses, protecting sensitive data is absolutely critical. Datasets containing personal information, such as PII (Personally Identifiable Information), PHI (Protected Health Information), or financial records, are particularly vulnerable to breaches and unauthorized access. In fact, more than 62% of organizations find it difficult to meet regulations like GDPR and CCPA, while over 90% of business leaders have already invested in AI and machine learning to address these issues.
One major risk comes from using unverified crowdsourced annotators, which can lead to confidentiality breaches. Additionally, threats like inference attacks, data aggregation vulnerabilities, and lateral attacks further compromise security. These challenges underscore the need for a well-structured and efficient approach to safeguarding data and meeting compliance requirements.
"The real risk isn't just a missing control. It's weak architecture. It's misplaced trust. It's assuming systems behave correctly when they fail." - Palo Alto Networks
How to Implement Secure and Compliant Practices
To tackle these risks, start by putting strong technical controls in place. Use AES-256 encryption, Multi-Factor Authentication (MFA), Single Sign-On (SSO), IP whitelisting, and Role-Based Access Control (RBAC). Following the Principle of Least Privilege ensures users only access the data they absolutely need.
Physical security also plays a key role. This includes measures like 24/7 monitoring and restricted physical access to secure facilities.
For data governance, prioritize the redaction of PII early in the process. This can involve manually or automatically removing sensitive details - such as dates of birth, national ID numbers, or bank account information - before sharing data. Another effective method is using signed URLs with short expiration periods (typically one day) to limit data exposure. Strengthen security further by adopting IAM delegated access, which grants platforms read-only permissions to your cloud-stored data. Lastly, ensure vendors meet rigorous standards by verifying they hold certifications like ISO 27001, SOC 2 Type II, or FedRAMP High.
"Data security is not a compliance checklist; it's a continuous operational requirement that protects your project and IP." - Sigma.ai
Improving Quality Assurance Workflows
Problems with Manual QA Processes
Manual QA processes often create roadblocks that make scaling difficult. Without clear, standardized guidelines, annotators might interpret data inconsistently, leading to sentiment labels that vary widely based on personal judgment. This subjectivity results in datasets that lack consistency, which can significantly hinder model performance.
Another major issue is scalability. Manually reviewing thousands - or even millions - of annotations is not only time-consuming but also impractical. These slow workflows delay project timelines, increase costs, and ultimately push back time-to-market. Fatigue among human reviewers compounds the issue, leading to errors like missed labels, incorrect bounding boxes, and unnoticed class imbalances. When these mistakes are caught late in the process, the cost of re-annotating data and retraining models can be overwhelming.
Moreover, many teams grapple with a lack of visibility. Fragmented workflows make it harder to detect errors in real time, leaving problems to pile up unnoticed.
Better QA Solutions
Addressing the challenges of manual QA requires a blend of automation and thoughtful human oversight. One effective approach is gold standard benchmarking, where expert-labeled "truth" datasets are used to evaluate annotator accuracy before they work on live data. By setting a minimum accuracy threshold - often 95% - teams ensure that only qualified annotators contribute to production datasets.
For subjective tasks like sentiment analysis or fraud detection, consensus workflows can help. These workflows assign the same task to multiple annotators (typically 3–5) and rely on majority voting to resolve disagreements. This method has been shown to reduce false positives by 18% in complex scenarios. Additionally, using metrics like Cohen's Kappa or Fleiss' Kappa to measure inter-annotator agreement can highlight areas where annotation guidelines need improvement.
Integrating programmatic QA with human oversight is another powerful solution. Programmatic QA uses scripts or automated tools to catch objective errors such as overlapping instances, incorrect word counts, missing attributes, or polygons that don’t meet minimum pixel thresholds. These automated checks provide real-time feedback, significantly cutting down on rework. AI-assisted labeling tools take this a step further, enabling 60% time savings by allowing human reviewers to focus on edge cases and corrections.
Strengthening QA workflows is critical for maintaining data quality throughout the annotation process, which is essential for successful AI deployments. A multi-tier review system can add several layers of quality control: annotators perform self-checks, peers review each other's work, and expert auditors catch subtle errors before the data reaches production. This approach is especially valuable for high-stakes applications like healthcare or autonomous driving, where implementing such oversight can result in 40% faster turnaround times.
"AI systems are only as smart as the data they're fed - and only as trustworthy as the humans who curate it." - McKinsey Analyst
Lastly, adopting living guidelines - regularly updated with visual examples of correct and incorrect labels - can help teams adapt to new edge cases as they arise. Instead of reviewing every annotation, automated queues can randomly sample assets or target high-risk categories prone to errors. For example, refining annotation rules for product categorization alone has been shown to boost accuracy by 22% in just one quarter.
Conclusion
Tackling common support challenges in annotation platforms is a critical step in ensuring the success of your AI projects. Data preparation takes up a significant portion of project timelines, and poor data quality remains one of the top reasons models fail to move beyond the proof-of-concept phase. This highlights why establishing a strong annotation infrastructure is so important.
The obstacles discussed in this article - ranging from integration issues and inconsistent data quality to scalability problems, cost overruns, security concerns, and QA inefficiencies - all lead to what experts refer to as "data debt." This debt builds up over time, forcing constant retraining of models. Addressing these issues head-on is the only way to break this cycle of inefficiency.
Here’s the good news: every challenge has a solution. For example, AI-assisted labeling can reduce annotation inconsistencies by more than 85% and shorten project timelines by as much as 75% compared to manual methods. Private deployments can save 30–50% in long-term costs for ongoing projects. Meanwhile, implementing robust QA workflows with gold standard benchmarks ensures that only qualified annotators contribute to your datasets.
Security and compliance also play a vital role in maintaining these improvements. With over 62% of companies struggling to adhere to regulations like GDPR and CCPA during AI implementation, selecting platforms with proper certifications and security protocols is essential. Beyond protecting sensitive data, strong security measures streamline project execution and safeguard your reputation.
FAQs
What are the best ways to maintain data quality and consistency in annotation projects?
Maintaining high data quality and consistency in annotation projects starts with establishing clear and detailed guidelines. These should include examples and decision trees to help annotators make consistent choices and reduce ambiguity.
To catch errors early, use a multi-step review process. This could involve annotators performing self-checks, followed by peer reviews, and concluding with final audits by supervisors. Adding automated validation tools and regular quality monitoring can further boost accuracy.
Equally important are strong communication channels and regular training sessions for annotators. These ensure that any issues are addressed quickly and that everyone stays aligned with project standards. When these strategies work together, they lay the foundation for reliable data to support your AI and machine learning models.
How can I reduce the high costs of using annotation platforms?
Reducing the costs of annotation platforms requires a smart mix of strategies that ensure both efficiency and quality. One way to cut expenses is by leveraging AI-powered tools like pre-labeling. These tools can handle repetitive tasks, reducing the need for extensive manual work and, in turn, lowering labor costs - all without sacrificing accuracy.
Another practical option is outsourcing annotation work to specialized service providers. This approach gives you access to skilled expertise and scalable resources without the overhead of building and maintaining an in-house team. Plus, it can free up internal resources for other priorities.
Investing in clear guidelines and implementing robust quality control measures is equally important. Clear instructions help prevent errors, while solid quality checks reduce the risk of costly rework, ensuring your data is ready to meet project requirements from the outset.
By combining automation, outsourcing, and a focus on quality management, you can strike the right balance between cost savings and delivering high-quality data for AI training.
How can I ensure security and compliance in data annotation?
To keep your data secure and compliant during the annotation process, it's essential to adopt robust protection measures in line with industry standards like GDPR, SOC 2, and ISO 27001. This means encrypting data both at rest and in transit, implementing strict access controls, and collaborating with providers that operate on secure infrastructure while adhering to strong privacy frameworks.
When selecting an annotation provider, look for those that emphasize confidentiality and have clear protocols for managing sensitive information, such as Personally Identifiable Information (PII) or Protected Health Information (PHI). Regular audits and strict adherence to applicable regulations will ensure your data remains protected throughout the entire annotation process.