Crowdsourced Annotation: Industry Trends 2025
· Data Annotation
Analysis of 2025 crowdsourced annotation: market growth, hybrid human-AI workflows, expert labeling, synthetic data, multimodal tools, and regulatory impacts.
Crowdsourced Annotation: Industry Trends 2025
Crowdsourced annotation is transforming the AI industry by prioritizing expert-level precision and quality over simple, high-volume tasks. In 2025, the market grew to $4.87 billion, driven by the demand for accurate data labeling in applications like generative AI, autonomous driving, and healthcare. Companies like OpenAI, Meta, and Google are investing billions annually in human-provided training data, while hybrid workflows combining AI and human oversight are cutting costs by up to 35% and boosting output fivefold.
Key trends shaping the industry include:
- Expert Annotations: Specialized professionals (e.g., radiologists, lawyers) are increasingly required for complex tasks.
- Regulations: Laws like the EU AI Act demand stricter oversight and error-free datasets for high-risk AI systems.
- Hybrid Workflows: AI-assisted platforms and human-in-the-loop systems are improving efficiency and accuracy.
- Synthetic Data: Over 60% of training data in 2024 was synthetic, addressing privacy and scalability challenges.
- Multimodal Annotation: Platforms now support simultaneous labeling of text, images, video, and 3D data.
The industry is evolving rapidly, with a shift toward data-centric AI development. Companies are leveraging advanced quality control methods, integrating AI pre-labeling with human validation, and adopting multimodal tools to meet the growing demand for high-quality training data.
If in a Crowdsourced Data Annotation Pipeline, a GPT-4
sbb-itb-cdb339c
Market Growth and Trends in 2025
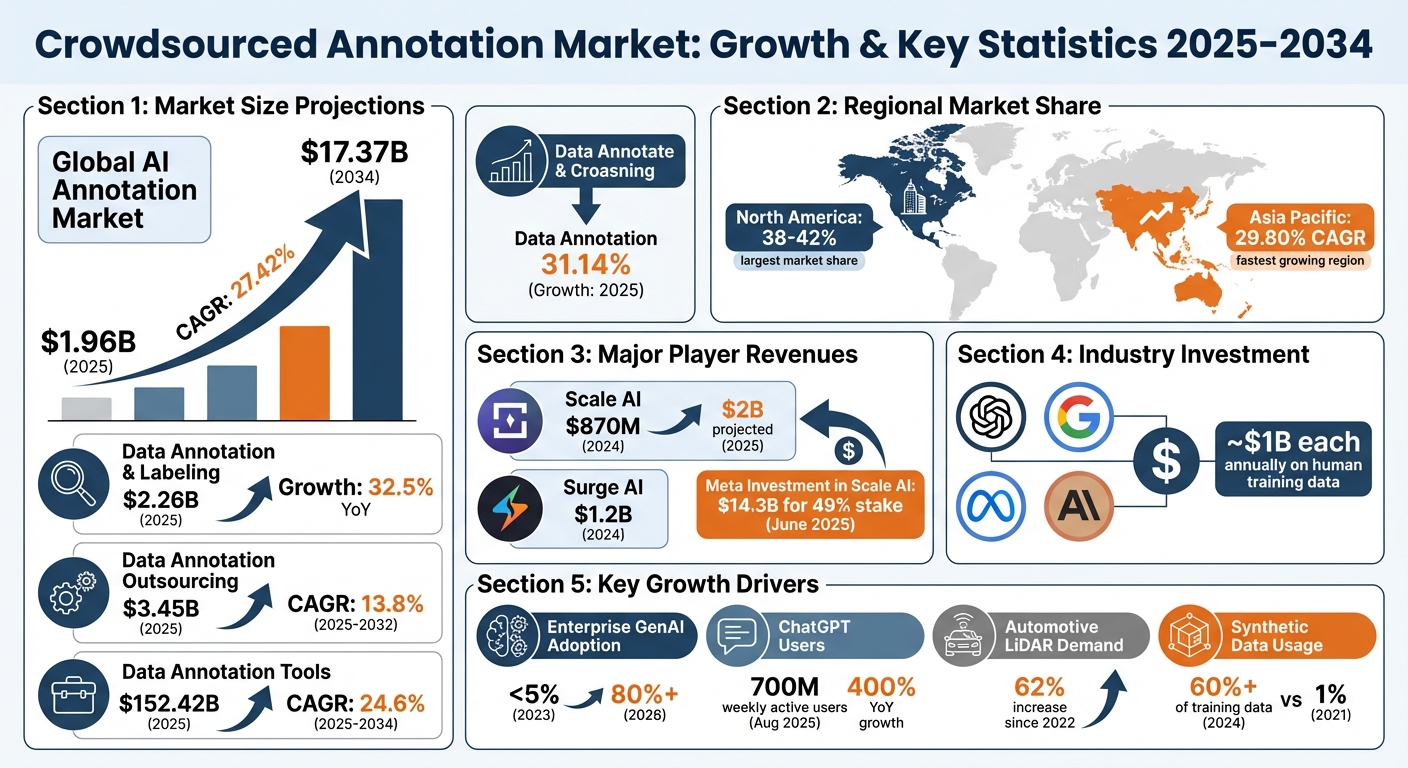
Crowdsourced Annotation Market Growth and Key Statistics 2025-2034
What's Driving Market Growth
The crowdsourced annotation market is expanding at an impressive pace, fueled by multiple factors coming together. Major AI labs like OpenAI, Google, Meta, and Anthropic are each spending around $1 billion annually on human-provided training data. This marks a major shift in how these companies prioritize data quality and sourcing.
The explosion of generative AI and large language models has redefined what annotation entails. It's no longer just about tagging images; now, tasks include Reinforcement Learning from Human Feedback (RLHF), where annotators rank, critique, and generate high-quality text to improve model outputs. These tasks require specialized expertise - think doctors, lawyers, or senior software engineers - rather than general crowd workers. This shift is further driven by stricter regulatory demands.
Regulations are also playing a key role in shaping this market. For instance, the EU AI Act requires training datasets for high-risk AI applications to be "error-free and complete", which means companies need professional, auditable validation. This has made loosely verified crowdsourced data inadequate for industries like healthcare, autonomous driving, and financial services.
Meanwhile, the rise of multimodal AI systems has added layers of complexity to annotation. These systems need simultaneous labeling of text, images, videos, and even 3D sensor data like LiDAR, especially for applications like autonomous vehicles and spatial computing. The automotive industry alone has seen a 62% increase in demand for LiDAR data annotation since 2022. All these trends highlight the growing need for high-quality annotation services.
Market Growth Projections and Data
The numbers paint a clear picture of rapid growth. The global AI annotation market is expected to climb from $1.96 billion in 2025 to $17.37 billion by 2034, with a compound annual growth rate (CAGR) of 27.42%. Another estimate places the broader data annotation and labeling market at $2.26 billion in 2025, up from $1.7 billion in 2024 - a year-over-year growth rate of 32.5%.
Regional trends also highlight key opportunities. North America holds the largest market share, ranging from 38.20% to 42%, thanks to its concentration of AI labs and tech leaders. At the same time, the Asia Pacific region is growing rapidly with a projected CAGR of 29.80%, driven by cost-efficient labor and emerging tech ecosystems.
Revenue figures from major players underline the market's momentum. Scale AI, for instance, reported $870 million in revenue in 2024 and is on track to hit $2 billion in 2025. In June 2025, Meta made headlines by investing $14.3 billion for a 49% stake in Scale AI, valuing the company at around $30 billion. Surge AI also saw strong performance, generating $1.2 billion in revenue in 2024 by supplying expert annotators to top AI labs.
The pace of enterprise adoption is accelerating, too. By 2026, over 80% of enterprises are expected to have deployed GenAI-enabled applications, up from less than 5% in 2023. This surge is driving sustained demand for annotation services. For example, on August 4, 2025, OpenAI revealed that ChatGPT had reached 700 million weekly active users - a staggering 400% year-over-year growth - further amplifying the need for high-quality training data.
| Market Segment | 2024/2025 Value | 2031-2034 Projection | CAGR |
|---|---|---|---|
| Global AI Annotation Market | $1.96B | $17.37B | 27.42% |
| Data Annotation & Labeling | $2.26B | N/A | 32.5% (2024-2029) |
| Data Annotation Outsourcing | $3.45B | N/A | 13.8% (2025-2032) |
| Data Annotation Tools | $152.42B | N/A | 24.6% (2025-2034) |
Quality Over Quantity: The New Industry Standard
The crowdsourced annotation industry has undergone a major shift in priorities since 2025. Instead of aiming for high-volume labeling, the focus has moved to precision, expertise, and verifiable quality. This change stems from stricter regulations, the complexity of generative AI, and the critical nature of modern applications.
Currently, around 80% of machine learning efforts are dedicated to data preparation and labeling. Poorly annotated data can significantly harm AI model performance - by as much as 30%. In one experiment, issues like missing or misaligned bounding boxes caused tracking accuracy to drop from 73.6% to 54.2%.
"AI development in 2026 no longer centers primarily on model architecture; the industry has shifted toward a data-centric reality where AI training data quality is the primary constraint." – Humans in the Loop
Regulatory frameworks are speeding up this transformation. The EU AI Act (Article 14), fully enforceable by August 2, 2026, mandates that high-risk AI systems must allow effective oversight by "natural persons". This includes documenting every data label's lineage and addressing bias. Generative AI tasks add another layer of difficulty - while traditional image classification can achieve over 98% accuracy, tasks requiring interpretation of tone, empathy, or reasoning often see agreement levels between 75% and 85%. These evolving demands highlight the need for specialized training and rigorous quality checks.
Domain-Specific Annotator Training
Gone are the days when generalist crowd workers could handle all annotation tasks. Modern AI projects demand experts who can navigate nuanced, ambiguous, or culturally sensitive data that algorithms might struggle to interpret. For instance, radiologists are essential for identifying subtle tissue differences in medical imaging, lawyers bring critical reasoning skills to legal AI systems, and autonomous vehicle projects require annotators trained in 3D LiDAR and sensor fusion.
Human judgment remains irreplaceable for complex tasks requiring deep contextual understanding. In 2024, the deep learning sector, which relies heavily on high-quality annotated data, accounted for 37.4% of the AI market. However, even expert annotators can show disagreement rates of 10–20% when interpreting emotions or narrative logic. This is why specialized training protocols are crucial. For example, the MIT SummEval project improved inter-annotator agreement (Krippendorff's alpha) from 0.41 to 0.71 by refining task instructions.
Expert-led workflows are also essential for preventing model collapse - a situation where AI systems trained on synthetic data begin replicating their own mistakes. High-quality, human-labeled data acts as a critical anchor, keeping models grounded in reality. Many organizations now use a hybrid approach: synthetic data for scalability paired with a curated, human-labeled subset as ground truth. This strategy helps balance production demands while ensuring models remain accurate.
Quality Control Methods
As annotators become more specialized, quality control practices have also advanced to maintain data integrity. In 2025, quality control moved beyond simple accuracy checks to include multi-layered validation processes that combine human expertise with rigorous mathematical methods. One effective strategy involves consensus and multi-reader validation, where several annotators independently label the same data, and a senior expert resolves disagreements.
Real-world examples highlight the impact of these methods. The VinDr-Mammo project, focused on breast cancer detection, used a dual-radiologist consensus to minimize labeling errors. Similarly, the LUNA16 Dataset for lung nodule detection required four radiologists to confirm each annotation. The Objects365 project adopted a multi-stage manual annotation pipeline to create 10 million detailed bounding boxes.
Consistency is now quantified using metrics like Cohen's and Fleiss' Kappa, with production-ready systems typically aiming for inter-annotator agreement scores of 0.8 or higher. Industry standards such as ISO/IEC 5259 have also been adopted to ensure data provenance, semantic accuracy, and dataset completeness.
Shift-left quality assurance has become a standard practice. Instead of waiting until the end of a project to assess quality, teams now run small "gold set" pilots at the start to catch ambiguities in instructions early. This approach prevents costly rework and ensures consistency throughout the workflow. Active feedback loops between machine learning teams and annotators further help avoid instruction drift.
Advanced techniques are also making a difference. For instance, minority report pruning estimates the likelihood of annotation disagreements based on factors like image ambiguity or annotator fatigue, cutting the total number of required annotations by over 60% without compromising quality. Model-in-the-Loop (MILO) frameworks integrate large language models to provide real-time feedback to annotators, ensuring fine-grained accuracy.
The human role in annotation is evolving. Instead of creating labels from scratch, annotators increasingly act as auditors, verifying and validating AI-generated labels for low-confidence or high-risk outcomes.
"Involving humans helps us avoid the vicious loop of 'AI training AI', which poses significant risks." – Communications of the ACM
For example, manual review of the Open Images dataset revealed that around 30% of individuals were initially left untagged. This underscores the ongoing necessity of human oversight, even with advanced automation. By combining expert judgment, mathematical validation, and strategic human involvement, the industry has built a quality control framework that meets both regulatory requirements and the technical demands of today's AI systems.
AI-Assisted Annotation Workflows
By 2025, teams are blending AI pre-labeling with human validation to speed up workflows and cut costs. This hybrid approach allows AI to handle repetitive tasks efficiently while humans step in to manage complex or ambiguous cases. The result? Up to 5x faster throughput and 30–35% lower data preparation costs.
AI-assisted platforms are also improving annotation accuracy by eliminating common manual errors, such as overlapping polygons or incomplete labels - boosting precision by 30%. Advanced tools like CrowdAgent use multi-agent systems to assign tasks dynamically based on complexity, leveraging both large and small language models alongside human expertise. Meanwhile, programmatic labeling platforms like ALCHEmist generate local label-producing code, significantly slashing costs. Together, these advancements set the stage for further refinement through strategic human interventions.
Human-in-the-Loop Systems
Human-in-the-loop (HITL) systems allow AI to handle around 80% of standard patterns, leaving humans to focus on the more challenging 20%. This division not only optimizes efficiency but also helps meet regulatory requirements like the EU AI Act, which mandates human oversight for high-risk AI systems.
Recent examples highlight the impact of HITL systems. In November 2025, OnsiteIQ, a construction intelligence company, transitioned to Encord's AI-assisted platform. This change cut project setup times from two months to just two weeks - a 75% reduction - and increased data throughput fivefold.
"Encord integrates seamlessly into our entire AI infrastructure. By implementing Encord within our redesigned ML infrastructure, we've established an efficient end-to-end workflow from data sampling through to model training." – Evgeny Nuger, Principal Engineer
Similarly, Pickle Robot, a warehouse automation company, adopted HITL workflows in late 2025 to address errors in outsourced labeling. This move boosted annotation accuracy by 30% and improved robotic grasping precision by 15%.
"For our AI initiatives, rapid iteration is critical. Encord and our ML infrastructure allow us to prototype learning tasks efficiently. The composability of Encord enables us to merge diverse data sources and experiment extensively." – Matt Pearce, Applied ML at Pickle Robot
The success of HITL systems hinges on clear criteria for human review. Typically, human intervention is reserved for low-confidence AI predictions or highly complex data. Techniques like active learning - where models identify data requiring human oversight - help streamline this process. While human oversight ensures immediate quality, it also feeds into long-term system improvements through continuous feedback.
Self-Learning Systems and Feedback Loops
Self-learning systems take annotation workflows a step further by creating feedback loops. Corrected labels are fed back into the system, helping the AI improve over time. As the system becomes more accurate, the need for manual intervention decreases, making the pipeline increasingly efficient.
For instance, in November 2025, Automotus, a traffic management company, implemented a feedback-driven approach. By combining automated data curation, AI-assisted labeling, and HITL feedback, they reduced the dataset size needed for annotation by 35% and cut labeling costs by over 33%.
"A shortcoming with other tools was the quality of the labels - bounding boxes were often too tight or too wide, or objects weren't classified correctly. With Encord, we can manage sampling rates, share real-time context, and help annotators perform better." – AI Team at Automotus
Emerging Model-in-the-Loop (MILO) frameworks represent the next step. These systems use large language models not only for pre-annotation but also as real-time assistants. They provide detailed feedback, monitor annotator performance, and flag inconsistencies, all while tracking metrics like error rates and confidence scores through integrated dashboards. This ensures task allocation between AI and humans is continuously optimized.
However, self-learning systems come with challenges. In subjective tasks like sentiment analysis, there’s a risk of bias if annotators rely too heavily on AI suggestions, potentially skewing the data. To counter this, organizations implement quality checks to ensure human auditors critically evaluate AI outputs, rather than simply approving them. Without this oversight, there’s a danger of creating a feedback loop where AI trains itself, which could harm model reliability.
These advancements reflect the growing focus on data-centric AI, pushing the boundaries of what's possible in annotation workflows.
New Technologies and Industry Developments
Advancements in quality standards and AI-driven methods are revolutionizing the way data is annotated, making processes faster and more efficient.
Synthetic Data and Real-Time Processing
Synthetic data has become a game-changer. By the end of 2024, over 60% of AI training data was synthetic, a massive leap from just 1% in 2021. Why? Real-world data often comes with challenges: it's scarce, expensive, or tied up in legal restrictions. Synthetic datasets solve this by providing privacy-compliant training material - think synthetic patient records for healthcare AI or simulated road hazards for autonomous vehicle testing - without violating regulations like GDPR or HIPAA.
The synthetic data market is expected to grow from $0.5 billion in 2025 to $2.7 billion by 2030. Researchers have already demonstrated its potential. In October 2025, the GRAID framework was applied to datasets like BDD100k and Waymo, generating over 8.5 million high-quality visual question-answering pairs. These synthetic data pairs achieved 91.16% human-validated accuracy, far outperforming earlier methods that only reached 57.6% accuracy. Similarly, in January 2026, Brighter AI helped Deutsche Bahn, Germany's national rail operator, train models in privacy-sensitive environments by providing GDPR-compliant video anonymization and synthetic augmentation.
Real-time annotation systems are another leap forward. These frameworks process live data - whether from sensors, cameras, or IoT devices - in just 50 to 500 milliseconds. This means AI models can adapt almost instantly to new situations. For example, real-time annotation can scan and label toxic content in live social media streams before it spreads. In healthcare, AI-assisted radiology systems can label medical scans as they are captured, giving doctors immediate insights. Edge-based annotation further boosts efficiency, cutting labeling time by more than threefold compared to traditional methods.
The industry is increasingly blending synthetic and real-world data into hybrid pipelines. Synthetic data fills gaps where real-world samples are unavailable or sensitive, while real-world data ensures models remain grounded in practical applications. Tools like Voxel51's auto-labeling technology pre-fill labels for human refinement, dramatically cutting costs. By integrating AI agents and auto-labeling, manual effort drops by about 50%, and costs are reduced fourfold. In some cases, combining synthetic datasets with minimal human involvement slashes the need for manual labeling by up to 70%.
These advancements in synthetic data and real-time processing are paving the way for more integrated and efficient annotation systems.
Multimodal Annotation Platforms
Modern annotation platforms are breaking down silos, moving toward unified workspaces that handle multiple data types - text, images, video, and audio - all within a single interface. For instance, Labelbox's "Label Blocks" allows annotators to work seamlessly across different modalities.
Other platforms are also innovating. Roboflow uses "prefix prompts" to streamline the creation of structured image-text pairs. SuperAnnotate offers tools like custom form builders and multimodal templates, complete with integrated model evaluation and cloud syncing. These systems ensure semantic and temporal alignment, so timestamps in audio match transcripts and image captions remain consistent with visual content. Unified ontologies further enhance consistency, ensuring that a "car" described in text corresponds to the same object in a video bounding box.
These tools are reshaping the role of annotators. Instead of manually labeling data, humans now focus on auditing and refining AI-generated labels. AI-assisted systems can cut annotation time by 60% to 80%, and hybrid workflows have been shown to boost throughput by up to 5×. Intelligent data selection and multimodal automation also lead to significant cost savings - up to 30% to 35%. On top of that, AI-assisted platforms reduce project setup time by 70% to 80%, thanks to workflow templates and intuitive interfaces.
These integrated platforms are not just streamlining workflows; they are redefining how annotation projects are executed, making them faster, more precise, and cost-effective.
How Data Annotation Companies Supports the Industry
With more than 100 vendors and a market projected to reach $17.37 billion by 2034, Data Annotation Companies (https://dataannotationcompanies.com) plays a key role in connecting organizations with specialized annotation providers. Acting as an industry hub, it simplifies the process of finding the right vendor, especially as demands for quality and domain-specific expertise grow in the AI-driven world. This centralized resource makes vendor selection easier by showcasing expertise and compliance standards clearly.
Directory of Service Providers
The platform organizes providers based on their domain expertise, including Text/LLMs, Autonomous Vehicles, Computer Vision, and Robotics/Speech. It distinguishes between major players like Appen and TELUS International, known for handling large-scale, multilingual projects, and boutique firms such as Surge AI and Mercor, which excel in specialized R&D tasks like reinforcement learning with human feedback (RLHF).
Businesses can evaluate providers using key criteria such as:
- Quality and Expertise
- Scalability
- Pricing
- Tooling
- Language Coverage
- Security and Compliance
- Flexibility
For sectors handling sensitive data, certifications like ISO 27001, SOC 2, HIPAA, and GDPR are highlighted. This focus is critical in an industry where over 80% of companies deploying AI rely on human-in-the-loop systems to refine model learning.
Resources for Industry Professionals
Beyond connecting businesses with providers, the platform also supports industry professionals by serving as a career and knowledge hub. The shift from low-margin outsourcing to strategic AI investments - such as Meta’s $14.3 billion partnership with Scale AI - has created new opportunities for annotation experts, particularly those skilled in areas like medical imaging, legal analysis, and autonomous vehicle data.
The platform offers professionals access to:
- Learning resources
- Industry insights
- Networking opportunities via newsletters and blogs
With the market expected to grow at a 27.42% annual rate through 2034, staying updated on trends like AI-assisted workflows and multimodal annotation is crucial. By 2025, an estimated 463 exabytes of data will be generated daily worldwide, underscoring the growing need for skilled annotators who can effectively collaborate with AI systems.
Conclusion
The crowdsourced annotation industry has shifted gears, now focusing on precise, expert-level labeling to complement AI's efficiency. This move away from generalist, high-volume tasks toward domain-specific precision mirrors the industry's growing emphasis on high-quality, data-driven outcomes. With projections estimating the market to reach $38.11 billion by 2035, having specialized expertise is no longer optional - it's essential. By November 2025, hybrid human-AI workflows showcased impressive results, including a 30% boost in annotation accuracy, up to 5x faster throughput, and cost reductions of 30–35%.
Regulations are also shaping this transformation. The EU AI Act's Article 14 mandates human oversight for high-risk AI systems. This legal requirement, paired with a stronger focus on data preparation, is redefining the role of annotators. They are evolving from manual labelers to critical quality gatekeepers.
"AI deployment is not a one-off event: continuous training shapes everything from user safety to regulatory risk and revenue."
- Conectys
The demand for skilled annotators is only increasing as multimodal platforms, real-time annotation needs, and synthetic data validation grow in importance. These trends highlight the need for professionals who can handle a variety of data types and modalities. Centralized platforms are stepping up to bridge the gap, merging human expertise with advanced technology.
Platforms like Data Annotation Companies play an essential role in this ecosystem. They connect organizations with specialized providers and equip professionals with tools to adapt to AI-assisted workflows, meet compliance requirements, and stay ahead of emerging trends. The future belongs to those who embrace this hybrid approach, combining human insight with machine efficiency to produce training data that stands out for its reliability and consistency.
FAQs
When should I use expert annotators instead of general crowd workers?
Expert annotators play a crucial role in AI tasks that demand precision, specialized knowledge, and careful judgment. Their expertise is indispensable for addressing complex scenarios, managing sensitive information, and navigating ethical challenges. They also ensure adherence to strict safety and regulatory requirements. While general crowd workers are effective for handling large-scale, straightforward tasks, experts bring the depth of understanding and accuracy needed to build trustworthy and reliable AI systems.
How can I make my annotation workflow compliant with the EU AI Act?
To meet the requirements of the EU AI Act, prioritize governance, documentation, and safety. Here's how:
- Keep detailed records: Document data sources and annotation processes thoroughly. This helps ensure traceability and accountability.
- Focus on data quality and security: Verify that your data meets high standards for accuracy and is protected against breaches or misuse.
- Evaluate compliance: Regularly assess how well your systems align with transparency and safety standards.
Additionally, stay informed about the latest EU guidelines and codes of practice to adapt to any changes. These steps highlight the importance of accountability, clear communication, and reliable data practices.
How can I balance synthetic data with human-labeled ground truth?
Balancing synthetic data with human-labeled ground truth is crucial for creating accurate AI models. Synthetic data is great for scaling up datasets and reducing costs, but it falls short when it comes to the nuanced, context-aware annotations that only human input can provide. By combining the two - leveraging synthetic data for volume and human expertise for validation - you can achieve both efficiency and quality. This hybrid method ensures datasets capture real-world complexity and align with human perspectives.