Human-in-the-Loop: Solving Annotation Quality Issues
· Data Annotation
How Human-in-the-Loop improves annotation quality with AI pre-labeling, human review, consensus and feedback loops to boost accuracy and reduce bias.
Human-in-the-Loop: Solving Annotation Quality Issues
- Inconsistent labeling: Annotators may interpret guidelines differently, leading to conflicting labels.
- Subjective interpretation: Tasks like sarcasm detection or sentiment analysis often vary based on personal or cultural understanding.
- Bias and edge cases: Annotators’ backgrounds can introduce biases, and rare scenarios can confuse automated systems.
Key HITL Benefits:
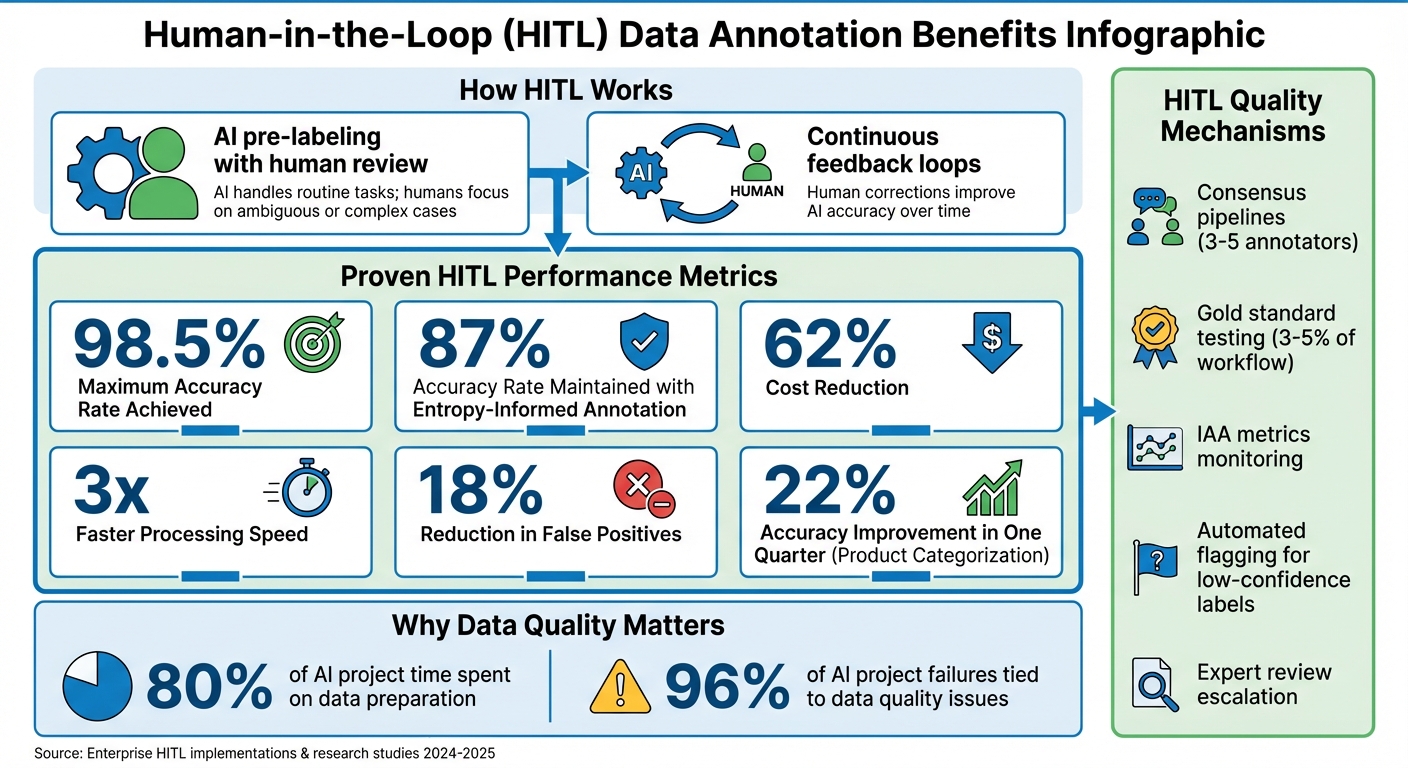
- AI pre-labeling with human review: AI handles routine tasks; humans focus on ambiguous or complex cases.
- Continuous feedback loops: Human corrections improve AI accuracy over time.
- Proven results: HITL systems achieve up to 98.5% accuracy, reduce costs by 62%, and cut false positives by 18%.
HITL ensures better data quality by blending automation with human oversight, making it essential for reliable AI performance.
Human-in-the-Loop (HITL) Benefits: Accuracy, Cost Reduction, and Performance Metrics
Why Humans Still Matter in Data Annotation | Human-in-the-Loop for VisionAI | Dataset Creation 🤝
Common Quality Problems in Data Annotation
Data annotation workflows often grapple with three major challenges that can directly impact the performance of AI models: inconsistent labeling, subjective interpretation, and bias in handling edge cases. Let’s break these down to understand why human oversight plays a crucial role in improving data annotation processes.
Inconsistent Labeling Between Annotators
When multiple annotators work on the same dataset, it's common for them to assign different labels to the same data points. This often stems from unclear or evolving guidelines. For instance, when labeling images of cars, one annotator might include side mirrors in the bounding box while another leaves them out - all because the instructions didn’t specify what to include. Without precise definitions, annotators rely on their own judgment, resulting in conflicting labels for identical objects. This inconsistency creates confusion for machine learning models during training, making them less reliable when faced with similar scenarios in real-world applications.
Subjective Interpretation Issues
Some data points are inherently open to interpretation, which makes consistent labeling a challenge. Take sarcasm in text, for example - what one annotator sees as sarcasm might not register the same way for another. Factors like an annotator’s first language, cultural background, or personal experiences can heavily influence how they interpret subjective content.
Studies show that linguistic nuances can drastically affect annotation outcomes. Annotators who lack cultural familiarity with a language often interpret content differently than native speakers. For example, a global e-commerce platform improved their annotation accuracy by 22% in one quarter after introducing clear rules for ambiguous categories, such as whether "smart fridges" should be classified under electronics or appliances.
Bias and Edge Case Handling Errors
Personal biases can creep into annotations, often reflecting the annotators’ unique perspectives. In one study on hate speech annotation, 48% of the annotators labeling English-language tweets were from Venezuela. This demographic imbalance introduced potential gaps in cultural and linguistic understanding, which could distort the dataset.
Edge cases - those rare, unusual data points that fall outside standard patterns - pose an additional hurdle. For instance, at DuckView Systems, an AI system misinterpreted a food-truck crowd as an aggressive mob because both scenarios exhibited similar motion patterns. Human reviewers caught the mistake by analyzing footage from multiple cameras, showing how critical context is in understanding edge cases. As Dan Wright, Founder of DuckView Systems, aptly put it:
"Edge cases hide in context, not pixels."
These types of errors can have real-world consequences. A financial services firm, for example, used consensus-based annotation to address subjective disagreements in fraud detection. This approach cut false positives by 18%, saving the company millions in operational costs.
What is Human-in-the-Loop (HITL)?
Human-in-the-Loop (HITL) combines the speed of artificial intelligence with the precision of human judgment to improve the quality of data annotation. Instead of depending entirely on automated systems or manual processes, HITL leverages the strengths of both. This approach helps address issues like inconsistent labeling, subjective errors, and bias in tricky edge cases. By creating a cycle of continuous improvement, HITL tackles many of the quality challenges that often plague data annotation.
Did you know that about 80% of an AI project’s time is spent preparing data? Even more striking, 96% of failures in AI projects are tied to data quality issues. By integrating human expertise into the machine learning process, HITL directly addresses these problems. This method sets the stage for critical steps like pre-labeling and ongoing refinement.
"Creating high-quality AI data is extremely complex and time-consuming, but essential for training, improving and evaluating Agents, models and really any enterprise AI system."
AI Pre-Labeling with Human Review
The HITL process often starts with AI pre-labeling. Here, models handle large volumes of straightforward tasks - like tagging common objects in images or classifying routine text. This reduces the manual workload significantly.
Human reviewers then step in to validate and adjust the AI's work. They focus on areas where the AI struggles, such as low-confidence predictions, complex edge cases, or tasks requiring subjective judgment. For instance, Hummingbird Technologies, an agricultural tech company, used a managed HITL team to annotate and review drone and satellite imagery. This allowed their in-house data scientists to concentrate on developing models rather than spending time on manual labeling.
To make this process efficient, many systems use confidence thresholds. Only the most ambiguous data points are sent to human reviewers, ensuring their efforts are concentrated on tasks where they add the most value. Research shows that using entropy-informed annotation can maintain an 87% accuracy rate, while cutting annotation costs by up to 62% and reducing the time required by a factor of three.
Continuous Feedback Loops
Once human reviewers correct the AI’s initial outputs, these corrections feed back into the model as new training data. This creates a dynamic feedback loop where the AI learns from its mistakes, gradually improving its accuracy.
This feedback loop plays a critical role in keeping models relevant. Over time, as real-world conditions and data patterns evolve, the loop helps prevent performance decline. Human annotators also ensure that algorithms handle exceptions and tricky edge cases effectively. Each correction strengthens the model’s ability to manage similar situations in the future.
The effectiveness of this collaborative approach is evident. For example, NextWealth reports that enterprises using their HITL feedback loop designs achieve an average accuracy rate of 98.5%. When implemented correctly, HITL proves to be a powerful method for maintaining high-quality data annotation and reliable AI performance.
How HITL Addresses Annotation Quality Problems
Now that we’ve covered how HITL operates, let’s dive into how it tackles the common quality challenges in data annotation projects. By blending machine efficiency with human judgment, HITL effectively addresses issues like inconsistency, ambiguity, and bias.
Building Consistency Through Consensus
Achieving uniformity across multiple annotators is a major hurdle in annotation projects. HITL solves this problem with consensus pipelines, where multiple annotators (usually 3–5) label the same data point. Discrepancies are then resolved through majority votes or a final review by a quality assurance manager. To measure consistency, teams often rely on Inter-Annotator Agreement (IAA) metrics like Fleiss' Kappa, which accounts for random chance.
Another key strategy is the use of gold standard testing. Pre-labeled "honeypot" questions are embedded into tasks to monitor annotator performance against known answers. Additionally, early calibration batches align annotators with project guidelines, while hierarchical reviews help maintain quality throughout the process.
| Quality Mechanism | Primary Function | Benefit for Consistency |
|---|---|---|
| Consensus | Multiple labels per unit | Resolves subjective disagreements |
| Honeypots | Hidden test questions | Detects deviations from guidelines |
| Calibration | Pre-production pilots | Ensures annotators understand expectations early |
| IAA Metrics | Statistical agreement | Measures reliability among annotators |
| Expert Audit | Senior-level review | Verifies accuracy in complex cases |
These mechanisms allow HITL systems to handle subjective disagreements and provide a framework for expert intervention when necessary.
Resolving Ambiguities with Expert Review
Subjective interpretation is another significant challenge in data annotation. HITL addresses this by forwarding uncertain predictions to human reviewers, ensuring that experts focus on areas where their input makes the most impact. This approach has been highly effective across various industries, with human review rates decreasing as models improve. Techniques like entropy-informed annotation and tiered expert escalation ensure that high-uncertainty cases are routed to senior reviewers.
Reducing Bias and Addressing Edge Cases
HITL goes beyond resolving ambiguity by actively identifying and mitigating biases, as well as handling rare or complex scenarios. Human experts play a crucial role in providing the context needed for difficult cases - such as sarcasm, idiomatic expressions, or multilingual nuances - that automated systems often misinterpret.
Active learning further improves quality by flagging data points where the model exhibits low confidence. These cases are then routed to human reviewers for precise labeling. This process also helps prevent model collapse, where systems trained on synthetic data become overly biased and lose alignment with real-world distributions. As Vahan Petrosyan, Co-founder & CEO of SuperAnnotate, explains, keeping humans involved is critical to maintaining high-quality results.
HITL workflows consistently outperform purely automated systems, achieving average accuracies of 96–98%, compared to 80–97% for automation alone. For example, Invensis Technologies applied a HITL layer to a logistics client’s invoice data extraction project in 2025. While AI managed structured data, human reviewers validated low-confidence outputs from handwritten annotations and non-standard formats. This boosted accuracy from 82% to 98% and cut processing time by over 40%.
sbb-itb-cdb339c
Best Practices for Implementing HITL in Annotation
Implementing Human-in-the-Loop (HITL) systems effectively requires a thoughtful combination of machine-driven processes and human expertise. Below are three strategies that annotation teams rely on to get the most out of HITL systems.
Using Consensus Mechanisms and Agreement Metrics
Consensus workflows involve assigning the same data point to multiple annotators - usually 3–5 people for tasks that are subjective or complex. Disagreements are resolved through majority voting or expert review. To determine how much overlap is needed, start by testing with 5–10% of your dataset. If disagreement rates are high, expand this percentage.
Inter-Annotator Agreement (IAA) metrics, like Cohen’s or Fleiss’ Kappa, are essential for tracking annotation consistency. Monitoring Pairwise and Aggregate Agreement can help identify when annotators deviate, signaling the need for retraining. If IAA scores dip below 0.6, consider updating your guidelines or providing more detailed examples.
For complex tasks, breaking them into smaller, more manageable sub-tasks can reduce cognitive strain and improve the reliability of consensus. Strong consensus mechanisms are key to maintaining high-quality annotations.
Gold Standard Testing and Calibration
Before scaling up any annotation project, start with calibration batches on a small data sample. This ensures your instructions are clear and that annotators understand the expectations. Incorporate qualification tasks - pre-annotated items with known correct answers - to evaluate annotator performance before they begin working on live data.
To maintain quality over time, randomly include 3–5% gold standard items in your workflow. These hidden checks allow you to monitor annotator performance without revealing which items are being tested. Regularly rotating these gold standards prevents annotators from memorizing answers. Some companies have reduced error rates by 50% by requiring annotators to achieve 95% accuracy on gold standard datasets.
Your gold standard dataset should represent all object classes and include challenging edge cases - not just straightforward examples. Keep it updated with new patterns encountered during the project to ensure it reflects real-world data. As highlighted in a Labelbox report:
"A project that was put together in a rushed or careless manner often leads to non-optimal or even unusable training data".
Once you’ve established a solid baseline for quality, automated flagging can further streamline the process by focusing on low-confidence labels.
Automated Flagging for Low-Confidence Labels
HITL systems often use confidence thresholds - such as 80% - to flag predictions that require human review. Active learning takes this a step further by automatically identifying and prioritizing low-confidence data points for human intervention.
For instance, in November 2024, Appen shared results from their "entropy-informed LLM annotation" study. By running multiple prompts through different large language models (LLMs) and calculating prediction entropy, they pinpointed low-confidence labels needing human review. This method maintained 87% accuracy while cutting costs by 62% and reducing annotation time by threefold. Similarly, Uber AI Solutions, in October 2025, described their HITL pipeline using the uLabel platform. This system calculates Cohen’s Kappa in real time, automatically flagging any drop in quality for human re-evaluation, enabling them to achieve 98% accuracy in data validation.
Consider tiered workflows to handle uncertainty more efficiently. High-uncertainty cases can be routed to subject matter experts, while standard cases go through peer review. Smart Validators can also be employed to catch formatting errors, gibberish, or duplicate submissions before they even reach the consensus stage.
Benefits of HITL in Data Annotation
Measurable Accuracy Gains
Human-in-the-loop (HITL) processes significantly improve annotation accuracy, surpassing the capabilities of automation alone.
Take Uber AI Solutions, for example. In October 2025, they implemented a HITL validation framework using the uLabel platform for their robotics and autonomous vehicle projects. By blending automated pre-labeling with expert reviews for tricky cases - like sensor reflections and occlusions - they achieved an impressive 98% accuracy rate.
Other examples highlight similar success stories. One case study showed that entropy-informed annotation maintained an 87% accuracy rate while cutting costs by 62% and tripling the speed. Another HITL refinement effort improved product categorization accuracy by 22% in just one quarter. These advancements demonstrate the leap from theoretical models to systems that consistently deliver in real-world scenarios.
Such accuracy improvements create a solid foundation for managing quality control as data demands grow.
Scalable Quality Control Methods
HITL doesn't just boost accuracy; it also scales effectively to handle massive datasets while maintaining high standards. It’s a solution that thrives on balancing automation with human expertise.
By combining automation with selective human review, teams can efficiently manage expanding data volumes. Instead of reviewing every data point, they typically assess 1–5% of random production outputs and focus on user-flagged errors. For larger projects, external providers can step in with workforces of over 1,000 trained labelers.
Active learning takes scalability one step further. Models can autonomously flag uncertain data points for human review, ensuring that human effort is concentrated where it matters most.
Vahan Petrosyan, Co-founder & CEO of SuperAnnotate, aptly sums it up:
"Creating high-quality AI data is extremely complex and time-consuming, but essential for training, improving and evaluating Agents, models and really any enterprise AI system".
Conclusion
Data annotation quality problems - ranging from inconsistent labeling to mishandling edge cases - can disrupt even the most advanced AI projects. A Human-in-the-Loop (HITL) approach offers a powerful solution by blending the efficiency of automation with the nuanced judgment that only humans can provide.
Organizations using HITL report impressive results: an 87% accuracy rate, a 62% reduction in costs, processing speeds that are three times faster, and an 18% decrease in false positives.
The key is to treat HITL as a collaborative system rather than just a quality control measure. Automation can handle routine pre-labeling tasks, while human expertise is reserved for subjective decisions, cultural nuances, and critical edge cases. For example, implementing gold standard testing - using around 200 expert-reviewed prompts - helps anchor each model version. Additionally, routing only low-confidence outputs (typically 1–5% of production data) to human reviewers ensures a balance between cost-efficiency and thorough coverage. This integrated workflow doesn’t just refine annotation processes; it strengthens the long-term reliability of your AI systems.
Andrej Karpathy captures this balance perfectly:
"We have to keep the AI on the leash. A lot of people are getting way overexcited with AI agents".
Automation may scale operations, but human insight remains essential for maintaining trust and dependability.
FAQs
How does Human-in-the-Loop enhance the accuracy of data annotation?
Human-in-the-Loop (HITL) takes data annotation to the next level by blending human expertise with machine learning. In this setup, human annotators play a critical role - they handle tricky or ambiguous data, fine-tune model predictions, and offer valuable feedback. The goal? To address the areas where machines might stumble, ensuring more accurate and reliable results.
This ongoing human involvement helps catch mistakes early and steadily boosts the model’s performance. By creating a continuous feedback loop, HITL not only sharpens data annotations but also builds a more dependable AI system over time.
How do humans help address bias and edge cases in data annotation?
Humans are key to enhancing data annotation quality by spotting and fixing biased labels that automated systems might overlook. They also step in to address ambiguous or rare edge cases, helping ensure datasets reflect real-world complexities more accurately.
This collaborative approach, often called human-in-the-loop, blends the speed of automation with the nuanced judgment and critical thinking that only humans can provide, making it invaluable for fine-tuning AI models.
Why is consensus important in Human-in-the-Loop processes?
Consensus is a crucial element in Human-in-the-Loop systems, ensuring data annotation is both accurate and dependable. By involving multiple annotators to independently label the same data and then merging their inputs - often through methods like majority voting - errors from individuals are reduced, leading to a more reliable final dataset.
This approach plays a key role in producing high-quality training data, which is critical for developing effective AI models. Additionally, consensus acts as a protective measure against bias and inconsistencies, helping to ensure the data represents a fair and accurate viewpoint.