NER Data Labeling for AI: Ultimate Guide
· Data Annotation
Practical guide to NER data labeling: tagging schemes, workflows, quality control, tools, and best practices for accurate entity extraction.
NER Data Labeling for AI: Ultimate Guide
Named Entity Recognition (NER) helps AI identify and categorize entities like names, dates, and locations in text. But the success of NER models hinges on precise data labeling. Poorly labeled data can lead to unreliable results, while consistent, high-quality annotations improve accuracy significantly. For instance, standardizing annotations boosted one company's NER accuracy from 75% to 94%.
Key Insights:
- NER Basics: Identifies entities (e.g., "Elon Musk" → Person).
- Tagging Schemes: BIO and BIOES are common, with BIOES offering finer detail.
- Challenges: Class imbalance, ambiguous entities, and inconsistent annotations.
- Best Practices: Use clear annotation guidelines, double-annotation, and at least 1,000 examples per entity type.
- Tools: Options like Prodigy, Label Studio, and Doccano streamline workflows.
- Applications: From healthcare to finance, NER extracts actionable insights from unstructured text.
NER labeling isn’t just about tagging - it’s about creating reliable datasets that power AI systems across industries. Whether you're using manual methods or leveraging pre-trained models, the goal is the same: accurate and consistent data for better results.
Automating NER Data Labeling with Few-shot Learning and UBIAI | Text Annotation | Karndeep Singh
sbb-itb-cdb339c
NER Tagging Schemes and Methods
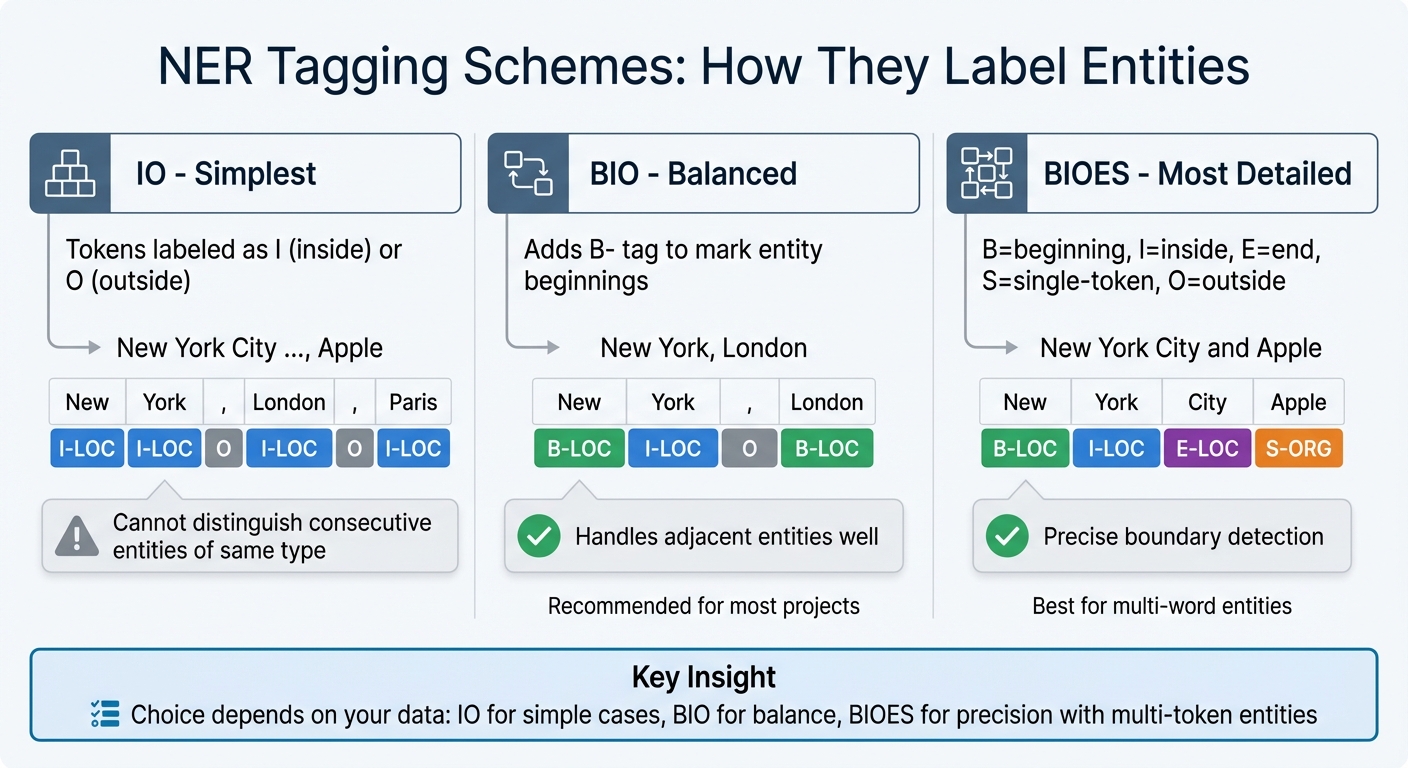
NER Tagging Schemes Comparison: IO vs BIO vs BIOES
When working with Named Entity Recognition (NER), choosing the right tagging scheme is crucial. It defines how entity boundaries are marked and directly impacts the model's ability to interpret your data. The choice often depends on the specific characteristics of your dataset.
Common Tagging Schemes Explained
The IO (Inside-Outside) scheme is the simplest approach. Tokens are labeled as either "I" (inside an entity) or "O" (outside an entity). While straightforward, it struggles with distinguishing consecutive entities of the same type. For example, in the phrase "New York, London, Paris", the IO scheme might treat all three city names as one continuous entity.
The BIO (Beginning-Inside-Outside) scheme addresses this limitation. It introduces the "B-" tag to mark the beginning of an entity. The first token of an entity gets a "B-" tag, while subsequent tokens are labeled with "I-." This distinction allows the model to recognize separate entities, such as "New York" and "London", even when they appear next to each other.
BIOES (also known as BILOU or BMEWO) goes a step further. It uses "B" for the beginning, "I" for inside tokens, "E" for the end of multi-token entities, "S" for single-token entities, and "O" for non-entity tokens. This scheme provides more detailed information, helping the model precisely identify where entities start and end.
| Token | BIO Tag | BIOES Tag | IO Tag |
|---|---|---|---|
| Multi-word: "New York City" | |||
| New | B-LOC | B-LOC | I-LOC |
| York | I-LOC | I-LOC | I-LOC |
| City | I-LOC | E-LOC | I-LOC |
| Single-word: "Apple" | |||
| Apple | B-ORG | S-ORG | I-ORG |
This table highlights how different schemes handle token labeling, particularly for multi-word and single-word entities.
Challenges in NER Labeling
One of the biggest hurdles in NER is class imbalance. In most datasets, "O" tokens (non-entity tokens) dominate, often exceeding 60% of the total. This can lead to models achieving high accuracy by simply predicting "O" for everything, which is entirely unhelpful. To address this, techniques like weighted loss functions are essential during training.
Choosing the Right Tagging Scheme
For most projects, BIO strikes a good balance between simplicity and effectiveness. It handles adjacent entities well without adding unnecessary complexity. If your dataset includes long, multi-word entities where boundary precision is critical, BIOES can offer slight accuracy improvements.
In some cases, simpler schemes like IO might outperform complex ones. For instance, experiments with Arabic NER and steel e-commerce datasets showed that IO produced higher F1 scores than BIO or BIOES. As Shannon Rong explains:
"Using which annotation scheme is really up to the data, the language and the use case".
Before committing to a tagging scheme, analyze your dataset. If consecutive entities of the same type are rare, a simpler scheme like IO might suffice. However, for datasets with frequent multi-token entities - such as legal references or medical terms - BIOES can provide the model with more precise boundary information, which can improve results.
Lastly, ensure logical consistency in your model's predictions. Enforcing valid tag transitions during decoding, such as using CRF layers, prevents errors like an "I-PER" tag following a "B-LOC". This step is essential for maintaining the integrity of your tagging rules.
The tagging scheme you choose will shape your entire labeling workflow and influence the accuracy of your NER model. Careful consideration of these factors is key to building a reliable and effective system.
Best Practices for NER Data Labeling
Creating high-quality Named Entity Recognition (NER) datasets requires more than just tagging text. The way you structure your labeling process can make the difference between a model that struggles and one that delivers reliable performance.
Maintaining Accuracy and Consistency
Consistency among annotators is crucial for reliable NER data. If different annotators label the same text inconsistently, your model ends up learning conflicting patterns. To address this, use metrics like Cohen's kappa for two annotators or Fleiss' kappa for larger teams to measure agreement levels.
Before diving into full-scale labeling, start with a pilot project. Have at least three annotators independently tag data for a couple of days. This helps pinpoint unclear guidelines and areas prone to natural disagreements. For example, variations in how the same organization name is labeled across data sources can significantly affect the model's accuracy.
Categorize and track common errors such as incorrect entity types, boundary detection mistakes, missed entities, or context-based ambiguities. Regularly review these issues during team meetings to refine your guidelines and prevent repeated mistakes.
As a general rule, aim for at least 1,000 examples of each entity type to train a robust machine learning model. However, for initial training and benchmarking, even 50 labeled examples per entity type can provide a good starting point.
Consistency naturally improves when annotation guidelines are clear and adaptable.
Writing Clear Annotation Guidelines
Annotation guidelines should evolve based on the task's requirements. These guidelines should explain the task's purpose, provide detailed descriptions of each entity type, and include plenty of examples - both positive and negative.
Negative examples are especially helpful. For instance, if you're tagging locations, specify whether terms like "American" or "French" should be included. Clarify edge cases, such as whether "April" should be tagged as a month or a person's name. Similarly, explain how to handle metonyms like "The White House", which could be tagged as a location when referring to the building or as an organization when describing the decision-making body. When the context is unclear, instruct annotators to default to the term's literal meaning.
Define span rules clearly. Should annotators include punctuation or possessive markers? For example, decide if "University of Washington" should be tagged as one organization or split into separate location entities. For specialized domains, hierarchical labels (e.g., "Defect → Crack → Hairline Crack") can provide the granularity needed.
Meta's Llama 3 model, trained on 10 million human-annotated examples, underscores the importance of clear guidelines at scale. In one case study involving a banking chatbot, refining data and prompts boosted the model's F1 score from 50 to 69.
Handling Ambiguous and Overlapping Entities
Even with clear guidelines, ambiguity and overlap are inevitable. Systematic strategies are key to resolving these challenges. For ambiguous entities, use the "Wikipedia Test" to determine the primary category based on its Wikipedia page. If the context is missing and the term is ambiguous, default to its most common usage.
Nested entities, like "Barack Obama" (Person) within "United States" (Location), require specific rules. Decide whether to annotate only the longest span or allow multiple levels of tagging. Some platforms support up to 15 levels of nested tagging, enabling detailed annotations within already labeled spans.
As Harman Singh, Senior Software Engineer at StudioLabs, puts it:
"Treating NER as a contextual understanding problem rather than a pure classification task was a key breakthrough".
Context-aware methods can help distinguish identical terms. For example, Shankar Subba, Head of SEO at WP Creative, tackled the ambiguity of "Python" (programming language vs. reptile) by combining part-of-speech tagging, dependency parsing, and transformer models like BERT.
Double-annotation enhances quality control. Have two annotators independently label the same data, followed by an adjudication phase to resolve differences. This process not only identifies subjective interpretations but also forces teams to clarify guidelines. As Cassie Kozyrkov, Chief Decision Scientist at Google, notes:
"Ground truth isn't true. It's an ideal expected result according to the people in charge".
Your annotation choices directly shape your model's learning. Make those choices thoughtfully, document them thoroughly, and update your guidelines as new edge cases arise.
NER Data Labeling Workflows and Tools
To ensure smooth and efficient Named Entity Recognition (NER) data labeling, you need a solid workflow and the right tools to back it up. Let’s break it down.
Standard NER Labeling Workflow
A step-by-step workflow is crucial to keep your NER project organized. It usually starts with data preparation, which includes collecting text, tokenizing it, and applying initial POS tagging and chunking. This sets the stage for annotation.
Next, you’ll need to define your ontology - essentially, a list of entity categories like Person, Location, or Organization, along with their attributes. To maintain consistency, detailed annotation guidelines with examples of what to include or exclude are essential. During the labeling phase, annotators manually or semi-automatically highlight text spans and assign labels.
Quality control is a must. Double annotation, where multiple annotators label the same data, helps resolve discrepancies. Post-processing then handles nested entities and formats the output into JSON, XML, or CSV files.
Efficiency matters, and tools like keyword lists or regex pre-highlighting can cut manual work by up to 50%. For example, one team labeled 949 food ingredient annotations in just 2.5 hours with 85% accuracy. In another case, a fashion industry project achieved 82.1% accuracy after annotating 1,735 examples in 2 hours.
Advanced techniques like active learning and programmatic labeling can also make a big difference. Active learning focuses on uncertain examples, while programmatic labeling uses rules to tag thousands of records automatically. As Joshua Odmark, CIO and Founder of Local Data Exchange, shared:
"The biggest hurdle we faced was handling inconsistent entity formats across different data sources... We solved this by implementing a custom fuzzy matching algorithm combined with a maintained database of entity variations, improving our recognition accuracy from 75% to 94%".
Once your workflow is in place, the next step is choosing tools that align with your goals.
Tools for NER Annotation
The right annotation tool can make or break your project. The choice depends on factors like team size, technical know-how, and the complexity of your task. Here are some popular options:
- Prodigy: A Python-based tool designed for rapid iteration with active learning. It integrates seamlessly with spaCy and costs $390 as a one-time fee per user.
- Label Studio: An open-source platform that handles complex tasks like overlapping annotations. Its Enterprise and Cloud versions range from $250 to $1,000+ per month.
- Doccano: A lightweight, web-based tool perfect for straightforward labeling tasks.
For larger-scale projects, Encord stands out for its ontology management and automated quality checks, while Snorkel AI specializes in programmatic labeling. LightTag is great for team collaboration, offering tools to resolve conflicts and track inter-annotator agreement.
When choosing a tool, look for features like AI-assisted labeling, support for nested entities, and built-in quality control. Kyle Hamilton, PhD Researcher at TU Dublin, highlighted the importance of a flexible approach:
"Label Your Data were genuinely interested in the success of my project, asked good questions, and were flexible in working in my proprietary software environment".
Using Pre-Trained Models in NER Labeling
Pre-trained models can speed up the labeling process while maintaining consistency. Tools like spaCy and BERT suggest entity spans and labels, so annotators only need to make corrections. Workflows like ner.correct help pre-highlight entities based on existing models.
Active learning ensures annotators focus on examples the model finds most confusing, while methods like ner.teach adapt models to new data. Transfer learning, which uses pre-trained weights from models like GPT-4 or BERT, enables your system to grasp broader context. For instance, Meta used 10 million human-annotated examples to train its Llama 3 model, showcasing how effective this approach can be.
Combining rule-based methods with machine learning often yields the best results. For instance, use patterns for fixed entities like "New York" and let the model handle context-sensitive cases. Cloud-based platforms with autolabeling features can further reduce manual work, often by 50% or more.
If scaling your NER project feels overwhelming, platforms like Data Annotation Companies can connect you with specialized service providers to streamline your workflow.
NER Applications and Future Developments
Industry Applications of NER
NER (Named Entity Recognition) plays a crucial role in helping businesses extract essential information from unstructured text across various industries. In healthcare, for example, it pulls out critical clinical details - like drug dosages, symptoms, and lab results - from patient records. This supports decision-making systems and automates processes like billing. Over in finance, NER processes documents such as invoices, bank statements, and receipts. It identifies vendor names, tax IDs, and monetary amounts, which helps with tasks like fraud detection and credit analysis.
E-commerce companies use NER to analyze customer reviews, identifying product defects or counterfeit listings. It also improves search accuracy by recognizing brand names and product-related intents. In legal tech, NER extracts key elements like parties, clauses, and jurisdictions from contracts. Meanwhile, cybersecurity teams rely on it to spot IP addresses, CVE IDs, and malware names in threat reports.
Despite these advances, a staggering 80–90% of enterprise data remains unstructured, with less than 18% being utilized effectively.
Domain-specific models have been game-changers here. Tools like BioBERT for medical terminology, FinBERT for financial documents, and LegalBERT for legal language have significantly improved performance in their respective fields. These specialized models are pushing the boundaries of what NER can achieve.
New Developments in NER Technology
Recent advancements are taking NER beyond traditional sequence labeling and into text generation tasks. For instance, models like GPT-NER use special tokens (e.g., "@@Entity##") to mark extracted entities directly within generated text. This approach proves particularly effective when training data is limited, outperforming many supervised models. Another innovation, DEER, employs label-guided in-context learning to help large language models select the most relevant examples. It achieves results comparable to supervised fine-tuning, but without the need for additional training.
Multimodal NER is another exciting area, combining text with visual data from scanned documents like forms and IDs. Few-shot learning techniques are also making waves, enabling models to recognize new entity types with minimal labeled data. Compact models like NuNER deliver high efficiency while being smaller and faster than larger, general-purpose language models.
To address challenges like hallucinations (where models incorrectly label non-entities), organizations are adopting self-verification methods. On the multilingual front, OpenNER 1.0, launched in 2025, offers standardized NER capabilities across 36 corpora in 52 languages, ensuring more consistent deployment worldwide.
Conclusion
High-quality NER data labeling isn't just a technical step - it's the bedrock of any successful AI model. As we've seen throughout this guide, the accuracy and consistency of labeled data directly impact whether your model produces reliable predictions or ends up delivering confusing, inconsistent results. The saying "garbage in, garbage out" couldn’t be more relevant here: poorly labeled data introduces noise that can lead to hallucinations and unpredictable behavior in production.
Here’s the upside: you now have a clear plan. Start by creating detailed annotation guidelines with examples that handle tricky edge cases, like distinguishing whether "Washington" refers to a person or a location. Use human-in-the-loop workflows that blend automated pre-labeling with human reviews - this combination consistently outperforms either method on its own. And for specialized domains like healthcare or finance, involve experts who can spot nuances that general annotators might overlook.
"The success of your ML models is dependent on data and label quality." - Scale AI
The stats back this up: effective NER implementation can improve document processing efficiency by as much as 60%. Plus, training with around 50 labeled examples per entity type can establish a solid baseline for performance. Whether you're working with medical records, financial documents, or customer feedback, the quality of your labels is what will ultimately determine the success of your AI system.
If you're ready to take on your NER project, explore the tools and workflows we've covered. From open-source solutions like spaCy and Doccano to commercial platforms with built-in quality controls, there’s no shortage of options. Need help finding the right annotation partner for your needs? Check out Data Annotation Companies for a directory of specialized providers tailored to your project goals.
FAQs
How do I choose between BIO and BIOES?
Choosing between BIO and BIOES depends on how precise you need your entity boundaries to be. BIO (Beginning, Inside, Outside) is straightforward and works well when exact boundary details aren't a top priority. On the other hand, BIOES (Beginning, Inside, Outside, End, Single) includes extra markers to identify the end of entities and single-token entities, making it better for tasks where boundary accuracy matters. If your focus is on detailed spans, go with BIOES. If you prefer simplicity and want to keep annotation less complicated, BIO is the better choice.
How can I measure annotator agreement for NER?
Inter-annotator agreement (IAA) metrics are key to evaluating how consistently multiple annotators label the same dataset in Named Entity Recognition (NER) tasks. These metrics help gauge the reliability of annotations and pinpoint areas where inconsistencies or ambiguities arise.
Common IAA methods include:
- Binary agreement: Measures whether annotators agree on the presence or absence of an entity.
- Document-level agreement: Assesses consistency across entire documents.
- Advanced metrics like Krippendorff’s α: Useful for more complex annotation tasks, providing a nuanced look at agreement.
By assessing IAA, you can ensure your dataset is dependable and identify areas where guidelines may need refinement or clarification.
When should I outsource NER labeling?
Outsourcing Named Entity Recognition (NER) labeling can be a smart move when managing it in-house becomes too expensive, time-intensive, or hard to scale. Some telltale signs include skyrocketing labor costs, unpredictable project timelines, or difficulties in finding and training skilled labelers. By outsourcing, you gain flexibility, the ability to scale quickly, and access to experienced annotators who can handle complex tasks. This approach helps maintain quality, keeps your project on track, and ensures you stay within budget.