How to Prepare Language Translation Datasets for NLP
· Data Annotation
Step-by-step guide to collecting, cleaning, tokenizing, batching, and validating parallel translation datasets for accurate NLP model training.
How to Prepare Language Translation Datasets for NLP
Your translation model is only as good as the dataset you train it on. High-quality language translation datasets are critical for accurate and context-aware machine translation. Here’s a quick breakdown of how to prepare these datasets effectively:
- Collect Parallel Text Data: Gather bilingual sentence pairs from trusted sources like OPUS, ParaCrawl, or Europarl. Ensure ethical data collection by checking licenses and respecting copyrights.
- Clean and Normalize: Remove noise like HTML tags, inconsistent encodings, and irrelevant data. Use tools to filter low-quality segments and align sentences correctly.
- Build Vocabulary and Tokenize: Create a manageable vocabulary with subword tokenization methods like BPE or SentencePiece for handling rare words and diverse scripts.
- Convert to Tensors: Transform tokenized data into tensors with attention masks and special tokens for training. Use batching techniques for efficiency.
- Annotate and Validate: Use human expertise to refine and review datasets, ensuring accuracy and minimizing errors.
Each step ensures your dataset is clean, aligned, and ready for effective NLP training. By focusing on quality over quantity, you’ll save resources and achieve better translation results.
Let's Recreate Google Translate! | Multilingual Data
sbb-itb-cdb339c
Step 1: Collect Parallel Text Data
Parallel text data consists of bilingual sentence pairs that are accurately translated. The effectiveness of your translation model heavily depends on the quality and variety of these sentence pairs, as they influence how well the model performs across various contexts and subject areas.
Ethical Data Collection
When collecting data, it’s crucial to respect copyright and ownership. For instance, ParaCrawl, a prominent web-crawled resource, adheres to a "Notice and Take Down" policy. They explain:
"We do not own any of the text from which these data has been extracted. We license the actual packaging of these parallel data under the Creative Commons CC0 license ('no rights reserved')".
While the packaged datasets are freely available, the original texts remain under copyright. Always check the licensing terms of any dataset you plan to use. Look for open licenses such as CC-BY, CC-BY-SA, or CC0. For projects involving sensitive data, consider anonymized formats like ROAM to safeguard personal information and comply with regulations like GDPR and CCPA.
Sources for Parallel Text
Once you’ve established ethical guidelines, the next step is to locate and acquire high-quality parallel text datasets from trusted sources. Here are some well-regarded options:
-
OPUS (Open Source Parallel Corpus): A comprehensive resource that compiles free online data, aligning it into formats like TMX, Moses, and XML for machine translation purposes. OPUS describes its mission as follows:
"OPUS is a growing collection of translated texts from the web. In the OPUS project we try to convert and align free online data, to add linguistic annotation, and to provide the data in various formats to make it easy to work with the data".
- ParaCrawl: Known for its large-scale web-crawled datasets, ParaCrawl primarily supports European languages but has expanded to include Asian languages. A November 2024 release added 9 language pairs, including Hindi, Vietnamese, and Indonesian paired with English.
-
Europarl: This resource provides professionally translated texts from European Parliament proceedings in 21 European languages. Its corpus (v7) includes approximately 60 million words per language and covers proceedings from 1996 to 2011. Philipp Koehn from the University of Edinburgh highlights its purpose:
"The goal of the [Europarl] extraction and processing was to generate sentence aligned text for statistical machine translation systems".
- EuroPat: Ideal for technical and specialized vocabulary, this source offers parallel sentences from the European Patent Organisation database. The second release, from September 2021, included 15.5 million English-German and 12 million English-French sentence pairs.
- JParaCrawl: For English-Japanese projects, this is the largest publicly available corpus created through automated web crawling and alignment.
When using web-crawled data, be prepared to handle noise. Tools like Bicleaner can help filter out low-quality sentence pairs, while TMXT simplifies converting data into usable formats. These tools are essential for ensuring your datasets maintain the level of quality required for effective machine translation.
Step 2: Clean and Normalize Text Data
After collecting parallel text data, the next step is to clean and normalize it. This ensures your translation model learns from consistent, high-quality input. Raw data often contains messy elements like HTML tags, irregular encodings, or formatting artifacts that can interfere with training. Michael Brenndoerfer, an NLP expert, puts it perfectly:
"Text preprocessing is the foundational step that transforms raw language into a structured format that computational models can work with".
Why does this matter? Proper preprocessing can have a huge impact. For example, aggressive cleaning methods can reduce vocabulary size by as much as 60–70% compared to minimal cleaning. In large-scale projects like ParaCrawl, cleaning and filtering can eliminate about 15% of raw segments, which significantly reduces training time per epoch.
Text Cleaning Techniques
Start by removing HTML tags and metadata with tools like BeautifulSoup. Use regular expressions to strip out URLs, email addresses, or social media markers. Then, apply Unicode normalization (NFC or NFKD) to make sure accented characters like "é" are represented consistently across your dataset.
Case normalization is another key step. Converting all text to lowercase prevents your model from treating "Translation" and "translation" as separate words, which would unnecessarily increase your vocabulary size. Expand contractions - turn "don’t" into "do not" - to provide cleaner tokens for analysis. Standardize punctuation (e.g., replace « or 《 with ") and remove non-printable characters.
Once you’ve standardized individual text elements, focus on removing low-quality segments with targeted filters.
Filtering and Length Constraints
Beyond basic cleaning, it’s important to filter out problematic text segments that could undermine your model’s performance. Start by removing segments that are blank or made up entirely of punctuation. Use language identification tools like Python's cld3 to confirm that each segment matches its intended language. Discard any segments containing unexpected scripts, such as a Japanese text with Tamil characters.
Segments over 300 words are often extraction errors and should be excluded. Also, check the length ratio between source and target segments - if one side is much longer than the other, it’s likely a misalignment issue. A common quality check is calculating the edit distance between source and target pairs; exclude pairs with an edit distance below 0.2, as they often indicate untranslated or copy-pasted text. Similarly, filter out pairs with mismatched numbers in the same numeral system, as this points to factual translation errors.
Lastly, confirm that your source and target files have the same number of segments. Any mismatch breaks the dataset’s parallelism, making it unusable for training. By following these steps, you’ll create a clean, reliable dataset that sets the stage for a strong translation model.
Step 3: Build Vocabulary and Tokenize Text
With your cleaned text ready, the next step is turning it into tokens. This involves constructing a vocabulary and applying subword techniques, both of which are crucial for your model's learning efficiency and ability to handle rare words.
Creating Vocabulary
The first step is scanning your training data to count how often each token appears. This helps you create mappings between tokens and their corresponding indices (both forward and reverse). To keep your vocabulary manageable and avoid overfitting, set a minimum frequency threshold (min_freq) to filter out extremely rare tokens.
Don’t forget to include special tokens like <PAD>, <SOS>, <EOS>, and <UNK>. These are essential for handling sequence boundaries and words that fall outside your vocabulary. For tasks like translation, starting target sequences with <SOS> and ending them with <EOS> can support strategies like teacher forcing.
For general-purpose models, vocabularies usually range from 30,000 to 100,000 tokens. For single-language models, a base of 32,000 tokens is a common starting point. Multilingual datasets, however, often require larger vocabularies - 100,000 tokens or more - to cover diverse scripts such as Chinese, Japanese, or Cyrillic. Keep an eye on fertility (the ratio of input tokens to output tokens). Aim for a range between 1.0 and 1.3. If your rate exceeds 1.5, it might be time to expand your vocabulary.
Implementing Tokenization
Subword tokenization has become the go-to method for translation models, outperforming traditional word-level techniques. Algorithms like Byte Pair Encoding (BPE), WordPiece, and Unigram are commonly used to break down rare words into smaller, more manageable subword units.
As Michael Brenndoerfer puts it:
"A poorly trained tokenizer can handicap an otherwise excellent model, forcing it to reconstruct meaning from character fragments that carry no intrinsic semantic signal".
Each tokenization method has its own approach. For example:
- BPE merges the most frequent adjacent character pairs in a greedy fashion.
- WordPiece, used in models like BERT, selects merges that maximize the likelihood of the training data.
- Unigram starts with a large vocabulary and prunes tokens based on a loss function, often yielding better results.
For multilingual tasks or languages without clear word boundaries, tools like SentencePiece or byte-level BPE are particularly effective. These language-agnostic approaches ensure consistent tokenization across diverse scripts.
Several tools are available to simplify this process, including HuggingFace's tokenizers library, OpenAI's tiktoken, and Google's SentencePiece. Before training your tokenizer, it’s a good idea to apply Unicode normalization (NFC) to keep token representations uniform. Inefficient tokenization can increase training costs by as much as 68%, so investing time in this step pays off. Once complete, your dataset will be ready for tensor conversion in the next stage.
Step 4: Convert Data to Tensors and Prepare Batches
Once your text is tokenized into integer IDs, the next step is to transform these IDs into tensors and organize them into training batches.
Tensor Conversion
Libraries like Hugging Face's transformers make it easy to convert token IDs into PyTorch or TensorFlow tensors while incorporating an attention mask. Don't forget to include special tokens like <CLS>, <SEP>, and <PAD> as needed. For example, BERT uses a vocabulary of 28,996 tokens and typically processes sequences of up to 512 tokens.
For translation tasks, you'll need to prepare target sequences for teacher forcing. This involves creating two versions of the target sequence: one that starts with a <SOS> token for the decoder input and another that ends with an <EOS> token to calculate the loss.
Once your tensors are ready, it’s time to focus on efficient batch preparation to streamline training.
Batch Preparation
Organizing tensors into batches is key to optimizing your training process. Use tools like torch.nn.utils.rnn.pad_sequence along with custom collate functions to dynamically pad each batch to its maximum sequence length. This approach prevents the inefficiency of padding the entire dataset to match the longest sequence.
Shuffling your data is important to reduce order bias. For GPU training, enabling pin_memory=True can lower data transfer latency, potentially improving performance by 5% to 15%. Batch sizes for NLP tasks typically range between 16 and 64 sequences, depending on your GPU's memory capacity. If memory is a constraint, you can use gradient accumulation to mimic larger batch sizes. This technique involves accumulating gradients over several smaller batches before updating the model parameters.
For datasets with sentences of varying lengths, implementing bucketing with a custom sampler can help reduce padding waste, speeding up the training process. Additionally, using the num_workers parameter in your DataLoader allows you to parallelize data loading across multiple CPU cores. However, if you're on Windows, you may need to set num_workers to 0 to avoid issues with multiprocessing.
Step 5: Annotate and Validate the Dataset
Once you've batched your data, the next critical step is ensuring translation accuracy and minimizing bias. This process refines your tokenized data into high-quality training inputs. Annotation and validation are where human expertise plays a key role, catching subtleties that automated systems might overlook.
Annotation Best Practices
Start by creating clear and straightforward annotation guidelines. Include examples of both correct and incorrect translations, and use visuals to make the instructions easier to follow. Testing the annotation process with a small pilot group can help identify any unclear points in the guidelines.
Human-in-the-loop systems are invaluable for capturing context and subtle nuances, especially in specialized areas like medical or legal translations. Breaking down complex translation tasks into smaller, more manageable subtasks helps annotators stay focused and deliver better results. AI-assisted pre-labeling tools can speed up the process by up to 80%, allowing human reviewers to concentrate on refining the more difficult cases.
Keep an eye on Inter-Annotator Agreement (IAA) scores, aiming for a score of 0.8 or higher. If scores fall below this threshold, it may signal unclear guidelines or ambiguities in the task itself. To keep everyone on the same page, maintain a shared FAQ document that records decisions and clarifications as they arise.
These steps lay the groundwork for a strong validation process that ensures the dataset is ready for training.
Validation for Quality Assurance
Building on the annotation guidelines, validation ensures the dataset meets quality standards through a structured review process. A multi-tiered approach works best: start with the initial annotation, follow up with a peer review, and then have experts adjudicate the most challenging cases. Using gold standard datasets - verified examples of accurate translations - helps benchmark annotator performance. You can also include hidden "honeypot" tasks to identify signs of fatigue or shortcuts in the labeling process.
"AI can be efficient, but it can't catch cultural nuances, context, or domain-specific accuracy like a pro linguist."
- The Translation Gate
To avoid bias, include diverse samples that represent various time periods, regions, and cultural contexts. Poor data quality isn’t just a technical issue - it’s expensive, costing organizations an average of $12.9 million annually. Addressing quality issues as they emerge allows you to update both the guidelines and the data in real time.
For highly specialized projects, consider partnering with expert data annotation providers. Platforms like Data Annotation Companies offer a curated list of professionals skilled in linguistic annotation and translation quality assurance. This final layer of validation ensures your dataset is fully prepared for NLP training.
Data Quality Evaluation Table
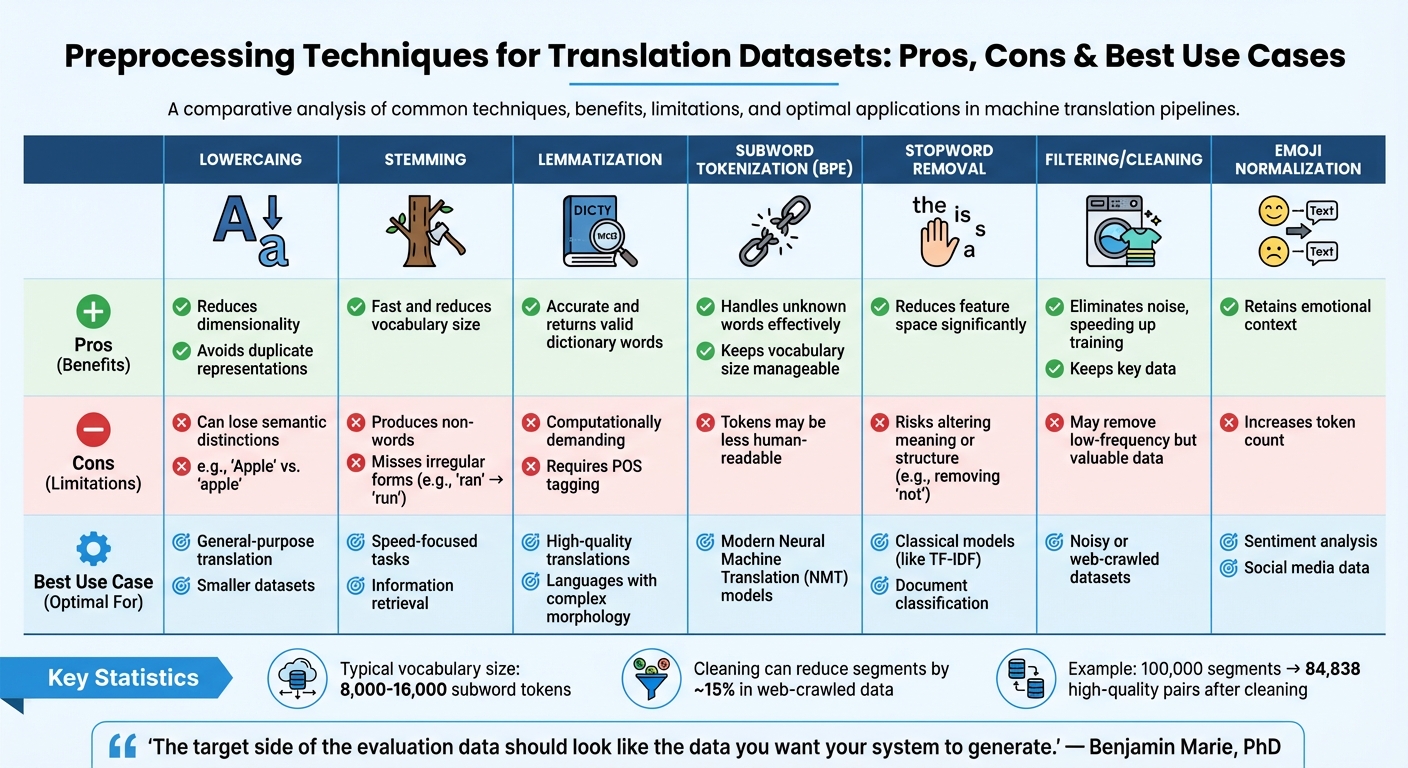
NLP Translation Dataset Preprocessing Techniques Comparison
Selecting the right preprocessing techniques depends on your model type, dataset size, and translation goals. Choosing poorly can waste computational resources or strip away crucial context that your model needs to learn effectively. The table below builds on earlier cleaning and tokenization steps, comparing how different preprocessing methods impact both data quality and model performance.
Preprocessing Techniques Overview
Each preprocessing approach has its strengths and weaknesses, and understanding them can significantly improve your translation model's output. While modern Transformer models thrive with minimal preprocessing, classical models often require more extensive cleaning to function efficiently.
Here’s a breakdown of common preprocessing methods, their trade-offs, and the scenarios where they shine:
| Technique | Pros | Cons | Best Use Case |
|---|---|---|---|
| Lowercasing | Reduces dimensionality; avoids duplicate representations | Can lose semantic distinctions (e.g., "Apple" vs. "apple") | General-purpose translation; smaller datasets |
| Stemming | Fast and reduces vocabulary size | Produces non-words and misses irregular forms (e.g., "ran" → "run") | Speed-focused tasks; information retrieval |
| Lemmatization | Accurate and returns valid dictionary words | Computationally demanding; requires POS tagging | High-quality translations; languages with complex morphology |
| Subword Tokenization (BPE) | Handles unknown words effectively; keeps vocabulary size manageable | Tokens may be less human-readable | Modern Neural Machine Translation (NMT) models |
| Stopword Removal | Reduces feature space significantly | Risks altering meaning or structure (e.g., removing "not") | Classical models (like TF-IDF); document classification |
| Filtering/Cleaning | Eliminates noise, speeding up training while keeping key data | May remove low-frequency but valuable data | Noisy or web-crawled datasets |
| Emoji Normalization | Retains emotional context | Increases token count | Sentiment analysis; social media data |
For most translation tasks, a vocabulary size between 8,000 and 16,000 subword tokens is typical. When dealing with noisy, web-crawled data, cleaning can cut down around 15% of segments, leading to faster training. For instance, cleaning a dataset of 100,000 segments left 84,838 high-quality pairs after deduplication and script filtering.
"The target side of the evaluation data should look like the data you want your system to generate."
- Benjamin Marie, PhD
To maintain benchmark comparability and ensure real-world accuracy, it’s critical to retain the original target data. These insights serve as a foundation for refining datasets before moving into the training phase.
Conclusion
Every step in the process - from gathering data to validating it - contributes to building a refined dataset that's essential for success in natural language processing (NLP). As Grammarly's engineering team aptly states:
"Your model is only as good as the data you use for training and evaluation".
The focus in NLP has shifted from sheer volume to prioritizing quality. Instead of training models from scratch on massive, noisy datasets, engineers are now fine-tuning pre-existing large language models using smaller, carefully curated multilingual datasets. This method not only conserves computational resources but also delivers more precise and contextually accurate translations.
Human expertise plays a key role in this quality-first approach, particularly in validating datasets. Experts are vital for addressing complex linguistic nuances and creating "gold data" for intricate language tasks. For instance, Human Science has contributed over 48 million high-quality training data pieces across various industries, showcasing the scale and importance of professional annotation.
Using in-domain corpora further boosts accuracy. Whether it's medical, legal, or technical content, domain-specific datasets significantly minimize the need for post-editing and improve precision in specialized areas. Lev Berezhnoy, Product Innovation Manager at Prompsit, highlights this advantage:
"Open datasets are a great start, but the richest data lies within your company. When a translation system learns from your support requests, work documents, and glossaries, it begins to speak in your brand's voice".
Starting with pilot annotations helps pinpoint issues quickly and ensures consistent quality control. To evaluate datasets effectively, use a blend of statistical metrics like BLEU and neural metrics such as COMET for a more thorough assessment.
FAQs
How big should my parallel dataset be to start?
The size of a parallel dataset largely hinges on your project’s objectives and the resources at hand. A good rule of thumb is to start with 100,000 to 200,000 sentence pairs, which often serves as a solid foundation. While larger datasets can enhance model performance - particularly for neural machine translation - don’t overlook the importance of data quality and proper alignment. These factors are crucial for achieving meaningful results during training.
What’s the fastest way to detect misaligned sentence pairs?
The quickest way to spot misaligned sentence pairs is by applying filtering methods like dual conditional cross-entropy. This technique measures divergence between sentence pairs using inverse translation models that rely on clean training data. By sorting or setting thresholds for these scores, low-quality pairs can be filtered out effectively.
Another option is leveraging pretrained multilingual models, such as XLM-RoBERTa, to assess semantic similarity. These models are excellent at pinpointing mismatches in meaning, making it easier to identify misaligned pairs.
Both approaches streamline the process of cleaning large datasets, which is crucial for NLP projects.
When should I use human review vs. automatic filtering?
When tasks demand high accuracy, nuanced judgment, or deep contextual understanding - like final quality checks or handling complex translations - human review is the way to go. On the other hand, automatic filtering shines in the early stages, handling simpler tasks like cleaning data, removing duplicates, or flagging glaring errors.
Human input guarantees precise linguistic accuracy, while automated tools efficiently process large volumes of data, helping save both time and effort. Together, they create a balanced approach to tackling diverse challenges.