How to Reduce Bias in Data Annotation
· Data Annotation
Practical steps—diverse teams, clear guidelines, bias training, QA, statistical checks, and synthetic data—to reduce annotation bias and improve AI fairness.
How to Reduce Bias in Data Annotation
Reducing bias in data annotation is crucial to ensure AI systems work fairly and accurately across diverse applications. Bias often stems from annotators' personal perspectives, unclear guidelines, or lack of diversity in annotation teams. This can lead to skewed datasets, impacting AI performance in areas like healthcare, hiring, and credit scoring. Here's how you can address these issues:
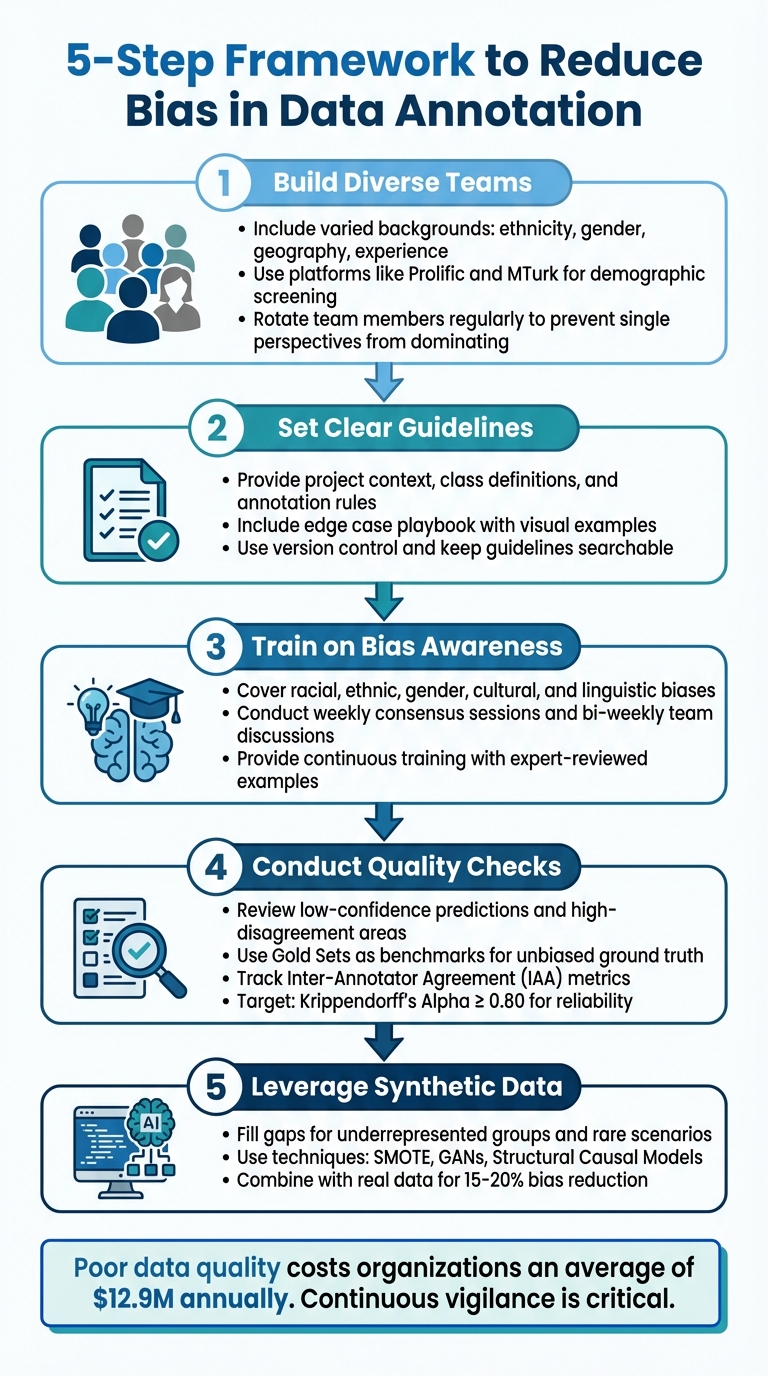
- Build Diverse Teams: Include annotators from varied backgrounds (e.g., ethnicity, gender, geography) to minimize blind spots.
- Set Clear Guidelines: Provide detailed instructions, edge case examples, and visual aids to ensure consistency.
- Train on Bias Awareness: Educate annotators about unconscious biases and provide strategies to handle ambiguous cases.
- Conduct Quality Checks: Regularly review annotations for inconsistencies and use statistical methods like stratified sampling to detect hidden bias.
- Leverage Synthetic Data: Use generated data to fill gaps for underrepresented groups or rare scenarios.
These steps help create balanced datasets, improving AI reliability while addressing ethical concerns. If managing this process in-house is challenging, consider partnering with experienced data annotation providers for expertise and scalability.
5-Step Framework to Reduce Bias in Data Annotation
Build Diverse Annotation Teams
Benefits of Diverse Teams
When annotators share similar backgrounds, they often have the same blind spots. Building a team that's diverse in gender, ethnicity, geography, and professional experience introduces a variety of perspectives that help identify biases others might miss. This doesn't just promote fairness - it directly enhances the quality of your data.
For example, language interpretation can vary widely across cultures. A slang term considered offensive in New York might be perfectly casual in London. Without diverse voices, your dataset could reflect only a narrow worldview. Even tasks that seem purely objective - like drawing bounding boxes - can show differences in accuracy depending on the labeler's ethnicity. A 2024 study involving 1,484 annotators and 45,000 annotations revealed that even factors like education level, often overlooked, significantly influence labeling decisions.
"When a diverse team of annotators collaborate, they can identify and challenge implicit biases that might otherwise go unnoticed." - Sigma AI
Diversity also strengthens counterfactual reasoning, which helps teams identify scenarios where a model might fail. By including people from different regions, you can capture subtle, region-specific nuances that a more uniform group might overlook.
How to Build Diverse Teams
To assemble a diverse annotation team, start by recruiting across multiple dimensions - not just gender and ethnicity, but also factors like age, geographic location, and education level. Platforms like Prolific and MTurk can help with demographic screening, but it's important to actively seek out underrepresented groups to counterbalance MTurk's predominantly white workforce.
Before scaling up, conduct a pilot round with a diverse test group. Have annotators from different backgrounds label the same data points and analyze disagreement points. These can highlight vague instructions or cultural assumptions in your guidelines. For specialized datasets, bring in subject matter experts to provide domain-specific insights that generalists might miss. To prevent any single perspective from dominating, regularly rotate team members and use consensus labeling, where multiple annotators label the same data points.
| Diversity Dimension | Why It Matters | Action to Take |
|---|---|---|
| Ethnicity/Culture | Affects slang interpretation, tone, and accuracy | Recruit annotators from a variety of regions and cultures |
| Gender | Shapes perception of subjective traits | Ensure balanced gender representation |
| Education/Professional | Adds nuance to technical and linguistic tasks | Combine generalists with subject matter experts |
| Geography | Reflects local norms and regional variations | Include annotators from areas where your AI will be used |
Building a diverse team is essential for creating clear, bias-aware annotation guidelines and ensuring your dataset reflects a broad range of perspectives.
sbb-itb-cdb339c
How Dataset Bias Destroys Your AI Model! 💥
Create Clear Annotation Guidelines
If your annotation guidelines are vague or incomplete, you’ll likely end up with inconsistent labels. This happens because annotators fill in the gaps with their own assumptions, which can introduce bias into the data set. A clear and detailed annotation brief is your best tool for reducing this risk. It shapes how annotators approach their tasks, what they focus on, and what they might overlook entirely.
What to Include in Your Guidelines
Start by explaining the project context - the "why" behind the task. Let annotators know how their work contributes to the bigger picture and the goals of the project. For instance, Google's search relevance guidelines encourage annotators to "use your judgment" 19 times, acknowledging that even the best instructions can’t cover every scenario. This kind of context helps annotators make informed decisions when they encounter ambiguous situations.
Next, include comprehensive class definitions. For every object class, provide a 1–2 sentence summary that highlights its key characteristics and visual indicators. Follow this up with clear annotation rules - explain exactly how data should be labeled. For example, specify when to use bounding boxes versus polygons, how to handle occlusions, or how to label objects with holes.
Don’t forget an edge case playbook. This is where you document tricky scenarios like occluded or blurry objects and outline how annotators should handle them. A great example comes from CloudFactory’s "Waste in the Wild" project in March 2023. Their guidelines defined "foreground objects" as those within 10 meters (about 33 feet) of the camera and included a "50% visibility" rule for labeling partially visible items. They also provided visual examples to help distinguish between similar objects like "Aluminum Foil" and "Batteries".
Visual aids are crucial. Include examples of correct and incorrect annotations to clarify expectations. Add a tooling walkthrough with instructions on how to use specific features in the annotation interface, such as masks, drop-down menus, or interpolation tools. Finally, establish feedback and escalation paths so annotators know how to flag uncertain cases or seek clarification.
| Guideline Component | Purpose | Key Elements to Include |
|---|---|---|
| Project Context | Motivation & Alignment | Purpose, goals, and data model context |
| Class Definitions | Accuracy & Precision | Summaries of each class, visual examples, and key features |
| Annotation Rules | Consistency | Tool usage, occlusion handling, and object labeling rules |
| Edge Case Playbook | Subjectivity Reduction | Rules for occlusions, partial visibility, and low-quality images |
| Logistics & Tools | Efficiency | UI walkthroughs, task time estimates, and escalation paths |
Once you’ve created detailed guidelines, the next step is to test and refine them to ensure clarity and consistency.
Test and Refine Your Guidelines
Even the most detailed guidelines need to be tested to ensure annotators interpret them correctly. Start by having a diverse group review the guidelines with a small data sample. This approach helps uncover regional, cultural, or dialectal biases that a more uniform team might miss. Additionally, ask project managers to try completing annotation tasks using only the written instructions. This can help identify areas that might be unclear.
Measure inter-annotator agreement (IAA) using metrics like Cohen's Kappa, Fleiss' Kappa, or Krippendorff's Alpha. For machine learning projects, a Krippendorff's Alpha of 0.80 or higher is considered reliable, while anything below 0.67 suggests issues with the guidelines or training. Low agreement scores often point to unclear instructions rather than annotator mistakes. Poor data quality isn’t just a hassle - it can cost organizations an average of $12.9 million annually.
Develop a gold standard dataset with expertly labeled examples to serve as a benchmark. This can help calibrate teams and assess whether the guidelines are clear. For instance, a global e-commerce company improved labeling accuracy by 22% in just one quarter after revising their product categorization rules.
Finally, treat your guidelines as a living document. Use version control to track updates, including dates, authors, and descriptions of changes. Platforms like Notion can make the guidelines searchable, allowing annotators to quickly find answers while working. Keeping the document updated ensures everyone is working from the same playbook.
Train Annotators on Bias Awareness
Even the clearest guidelines won’t eliminate bias if annotators aren’t aware of their own unconscious assumptions. Personal experiences and cultural backgrounds shape how annotators label data, which can unintentionally introduce bias. A 2024 study by the Association for Computational Linguistics revealed that natural language models often rely more on annotation patterns than on actual understanding of the world. This means any blind spots in your annotators’ work will likely carry over to your AI model. To address this, training programs need to focus on specific bias types and establish clear protocols for handling them.
What to Cover in Training
Annotators need to learn how to spot various types of bias, including racial, ethnic, gender, cultural, and linguistic biases. For example, racial and ethnic bias can emerge when datasets lack diversity - like facial recognition systems that perform poorly on darker skin tones because they were trained mostly on images of lighter skin. Gender bias often reflects historical inequalities, such as hiring data that favors male candidates or speech recognition systems that mishandle certain pronouns.
Cultural and linguistic bias is another critical area. Annotators must recognize regional dialects, African-American Vernacular English (AAVE), and non-Western slang to avoid mislabeling or misinterpreting context. The "Scunthorpe Problem" is a classic example, where innocent words are flagged because they contain substrings matching prohibited terms. Training should emphasize understanding context rather than relying solely on keyword detection.
It's also essential to tackle implicit and unconscious bias directly. Everyone brings personal and cultural perspectives to their work, which can affect their decisions. Make sure annotators understand the "hat" they’re supposed to wear - whether they’re labeling from a particular user’s perspective or as a neutral observer. Provide clear guidelines for handling uncertain cases, such as when to flag, escalate, or skip ambiguous data points.
Edge cases require special attention. Use real-world examples to illustrate challenging scenarios involving regional, dialectal, and multilingual variations. Conduct pilot rounds before full-scale implementation to identify areas where instructions might be unclear or prone to biased interpretations.
Provide Continuous Training
Training isn’t a one-and-done process. It should evolve to address new challenges and maintain high standards. Incorporate expert-reviewed examples into tasks, hold weekly consensus sessions, and conduct regular audit reviews to catch and correct systematic errors. Feedback loops are essential - allow annotators to log uncertainties and flag confusing cases, which can then inform updates to training materials.
Here’s a quick look at some recommended training practices:
| Training Type | Purpose | Recommended Frequency |
|---|---|---|
| Consensus Sessions | Reconcile disagreements and find new patterns | Weekly |
| Team Discussions | Create a space for learning and sharing | Bi-weekly |
| Audit Reviews | Address systematic errors and improve quality | Monthly |
| Formal Training | Refresh skills and reinforce bias awareness | Quarterly |
Adapt your training protocols immediately when systematic errors, data shifts, or quality drops are identified. With upcoming regulations like the EU AI Act and the U.S. AI Bill of Rights, maintaining detailed, ongoing training will soon be a compliance requirement rather than just a good practice.
"Every labeling decision encodes a value judgment, which means annotation standards become the ethical rules of the model." – Karyna Naminas, LinkedIn
Conduct Regular Quality Checks
Maintaining data integrity goes beyond simply identifying errors - it's about catching potential biases before they spread through your dataset. Even well-known datasets like ImageNet have been found to contain around 6% label errors. And when as much as 40% of labels in a dataset are incorrect, model performance can drop to just 46.5% of its potential. Regular quality checks are essential to spot these problems early, whether they arise from annotator habits or underrepresented subgroups that could distort your AI model’s behavior.
Review Sample Annotations
Focus on reviewing data that’s most likely to introduce bias. This includes low-confidence predictions, areas of high annotator disagreement, and tricky edge cases.
"I use QA to identify the most likely erroneous predictions in a real-world context, not random samples. I define slices representing the highest production risk: low confidence predictions, high disagreement between annotators, and domain-specific language that historically caused struggles." – Kevin Baragona, Founder of Deep AI
One effective strategy is to incorporate "Gold Sets" - expert-labeled data sprinkled throughout annotation tasks. These serve as benchmarks to ensure annotators stay aligned with unbiased ground truth. Additionally, track Inter-Annotator Agreement (IAA) using appropriate metrics. Low IAA scores often point to ambiguous guidelines, which can result in subjective or biased decisions. It's also crucial to check for class balance and representation of long-tail data to avoid overrepresentation of majority classes or certain demographics.
For example, between August 2025 and January 2026, AirSeed Technologies partnered with Label Your Data on a drone reforestation project involving 50 large geofiles. By implementing a pilot validation process and milestone-based checkpoints, they avoided rework entirely after the first production round.
Once these quality checks are carried out, structured feedback should follow immediately to drive continuous improvement.
Give Annotators Feedback
Feedback is most effective when it’s specific and actionable. Use in-tool comments to attach feedback directly to the data. Focus on delivering concise, grouped feedback that addresses high-impact issues. Annotators should also be encouraged to flag unclear instructions or edge cases during reviews. Reviewers must then respond, closing the loop and showing how feedback influences the project.
For instance, Nodar, a 3D computer vision company, adopted a feedback-driven workflow for its depth-mapping software. Their process included a pilot feedback phase, live training sessions, and regular updates to documentation. This system allowed them to scale to 20 annotators and 3 QA reviewers while managing 60,000 objects per dataset with minimal rework. Feedback sessions are also a chance to refine annotation guidelines. By documenting resolutions to ambiguous cases and updating the master instructions, teams can reduce recurring biases and improve the quality of future annotations.
Use Statistical Methods to Detect Bias
Quality checks are great for catching one-off mistakes, but statistical methods help uncover hidden patterns of bias across your entire dataset. These methods are particularly useful for identifying systematic issues - like underrepresented groups or uneven label distributions - that manual reviews might overlook. By using mathematical techniques, you can pinpoint where bias creeps in and address it early.
Use Stratified Sampling
Stratified sampling divides your dataset into specific groups (or strata) based on characteristics like age, gender, or ethnicity. This ensures that each group is properly represented in your annotated data. Without this approach, some groups might be over- or under-represented compared to their actual prevalence.
"Any sort of skew in your data, where certain groups or characteristics may be under- or over-represented relative to their real-world prevalence, can introduce bias into your model." – Google for Developers
A great example comes from March 2025, when researchers at the University of Maryland and LMU Munich introduced the Population-Aligned Instance Replication (PAIR) method. They worked with 3,000 English-language tweets, duplicating labels to reflect true population demographics. This approach significantly reduced calibration bias in hate speech detection models - without requiring new annotations. The takeaway? Audit model performance by subgroup, not just at the aggregate level. To do this, compare your annotator pool against national census data or reliable surveys and calculate weights that align with the general population.
Statistical analysis doesn’t just ensure balanced representation; it also helps flag irregularities that manual reviews might miss.
Analyze Outliers
Outliers - data points that stand out dramatically from the rest - can be red flags for errors or bias. When you find an unusual data point, dig deeper to determine if it’s a rare but valid occurrence or a mistake that could skew your model.
For instance, in December 2025, Google for Developers highlighted a hypothetical issue in a rescue-dog adoptability model. A Labrador Retriever’s age was recorded as 35 years - clearly an error, since the oldest dog on record is about 29 years old. This likely stemmed from a typo (e.g., 3.5 years entered as 35), signaling broader data quality issues. Tools like Cleanlab can help by automatically detecting label errors, outliers, and near-duplicates. Also, keep an eye out for missing feature values. For example, if 30% of a 5,000-example dataset lacks temperament data - and this missing information correlates with certain breeds or ages - you’ve uncovered a potential source of bias.
Balance Datasets with Synthetic Data
Synthetic data offers a forward-thinking way to address dataset imbalances, especially when real-world data falls short. Whether it's missing key demographics or lacking rare scenarios, synthetic data steps in to fill those gaps. This type of data is particularly useful for representing underrepresented groups or capturing edge cases that are hard to find or replicate in real-world datasets. It allows you to create balanced datasets without the delays associated with extensive data collection.
What is Synthetic Data?
Synthetic data is designed to replicate the statistical properties of real-world data. By mimicking these patterns, it provides realistic examples that models can learn from. For instance, in healthcare, synthetic patient records can replace real medical data, enabling the creation of large, diverse datasets while safeguarding patient privacy. Similarly, in autonomous driving, synthetic data can simulate rare conditions - like fog at dawn or unusual pedestrian behavior - that would be challenging to gather manually.
"Dataset diversity is thus key to successful real-world deployment. No matter how big the size of the dataset, capturing long tails of the distribution is impractical." – Nikita Jaipuria, IEEE
Various techniques are available for generating synthetic data, depending on the type of data needed. Examples include:
- SMOTE: Interpolates minority samples to balance datasets.
- GANs: Generates high-quality images and signals, achieving around 92% accuracy in replicating real ECG and EEG signals.
- Structural Causal Models: Produces data samples designed to minimize bias.
These methods not only supplement datasets but also improve fairness and diversity when combined with real data.
How Synthetic Data Reduces Bias
Synthetic data plays a crucial role in addressing bias by creating samples for underrepresented groups. For example, in October 2024, a study led by Draghi used anonymized Clinical Practice Research Datalink datasets to generate synthetic samples for underrepresented demographics. This approach reduced bias by 15–20% and improved precision accuracy by 10–12%, all while retaining 90–95% data utility. Similarly, in March 2024, Allen Chang and his team at the University of Southern California introduced the QDGS (Quality-Diversity Generative Sampling) framework at the AAAI Conference. They used the framework to balance a facial recognition dataset by generating samples with specific attributes like skin tone and age, which improved fairness across benchmarks without sacrificing overall accuracy.
Combining real and synthetic data often yields the best results. For instance, in June 2020, researchers Nikita Jaipuria and colleagues demonstrated this at the IEEE/CVF Conference. They used gaming engine simulations to generate synthetic data for autonomous vehicle tasks like parking slot detection and lane detection. By integrating synthetic data, they achieved better cross-dataset generalization compared to using real data alone. A practical workflow involves pre-training models on synthetic data to balance distributions, followed by fine-tuning with a smaller set of high-quality real-world samples. This hybrid approach bridges the gap between artificial and real-world complexities, creating a robust strategy for reducing bias throughout the annotation process.
Conclusion
Summary of Best Practices
Reducing bias in data annotation requires ongoing attention at every stage of the workflow. Start by assembling diverse annotation teams - different perspectives can help uncover biases that a uniform group might overlook. Develop clear, detailed guidelines with examples and edge cases to eliminate ambiguity, and keep these documents adaptable as project needs evolve. Regular bias-awareness training ensures your team stays aligned, while quality checks and methods like stratified sampling help identify issues early on.
"Preventing bias requires continuous vigilance - it's a critical operational challenge, not just a technical one." – Sigma AI
Using synthetic data to address gaps for underrepresented groups or rare scenarios can strengthen your dataset. When paired with human-in-the-loop verification, these steps create a robust system that minimizes inconsistencies and prevents them from escalating into larger problems. Poor data quality can be expensive - not just financially but also in terms of model reliability and user trust. By investing in measures like diverse teams, adaptable guidelines, ongoing training, and advanced quality controls, you set the foundation for a fair and effective data annotation process.
Finding the Right Data Annotation Partner
If building an in-house operation becomes too challenging, external partners can take these best practices to the next level. Establishing a team with the necessary expertise, scale, and diversity to minimize bias can be daunting. Specialized providers bring technical expertise, access to diverse global talent, and multi-layered quality assurance systems that catch potential issues before they affect your model. These partners can scale up to over 1,000 annotators while maintaining accuracy rates above 99% - a level of efficiency that's tough to match internally.
When choosing a provider, prioritize those with domain expertise, a diverse workforce, and managed services that actively address bias detection. Platforms like Data Annotation Companies can connect you with vetted providers, including TrainAI by RWS and Label Your Data, which offer flexible pricing and pilot programs. The right partner doesn’t just deliver labeled data - they become an extension of your team, ensuring your annotations reflect the diversity your AI will encounter in the real world.
FAQs
How do I measure annotation bias?
Measuring annotation bias focuses on evaluating how consistent and reliable annotators are when labeling data. One crucial approach is assessing inter-annotator agreement, which examines how often annotators assign the same labels to identical data points. If agreement is low, it might signal issues like bias or poorly defined guidelines. Another important step is reviewing score distributions across different demographic groups. This can help identify patterns of systemic bias, promoting fairness and accuracy in the labeling process.
How diverse should annotators be?
A diverse group of annotators is essential for reducing bias, ensuring data represents a broad spectrum of perspectives, and enhancing the fairness and accuracy of AI models. When a team includes people from various backgrounds, they can more effectively spot and address biases during data labeling, resulting in outcomes that are more balanced and dependable.
When should I use synthetic data?
Synthetic data serves as a practical solution when faced with challenges like limited data availability, privacy issues, or the high expense of gathering real-world data. By generating large and varied datasets that reflect real-world patterns, it supports the training of AI and machine learning models. Beyond that, synthetic data can complement existing datasets, test and validate models, or anonymize sensitive information - all contributing to improved model performance and more balanced outcomes.