Why Larger Datasets Increase Labeling Costs
· Data Annotation
Large datasets raise labeling costs due to annotation complexity, quality control, and specialist labor; hybrid automation, active learning, and human review reduce expenses.
Why Larger Datasets Increase Labeling Costs
When datasets grow, labeling costs rise exponentially - not just due to volume but because of added complexities like quality control, workforce management, and specialized infrastructure. Labeling typically consumes 80% of an AI project’s timeline, and poor planning can lead to delays and budget overruns. Key reasons for higher costs include:
- Annotation complexity: Tasks like pixel-perfect segmentation or 3D labeling cost significantly more than simple classifications.
- Quality control: Ensuring consistency in large datasets often requires rework, inflating costs by 20%-40%.
- Specialized expertise: Fields like healthcare or legal annotation demand domain experts, increasing hourly rates.
- Hidden costs: Rework, compliance, and vendor management can double or triple initial estimates.
To reduce costs, strategies like AI-assisted labeling, active learning, and a mix of automation with human review can cut expenses by 40%-80%. For instance, auto-labeling tools can process millions of labels in hours at a fraction of traditional costs. Ultimately, balancing cost, quality, and efficiency is crucial for large-scale AI projects.
Curate training data via labeling functions - 10 to 100x faster
sbb-itb-cdb339c
Why Large Datasets Cost More to Label
Large datasets push up labeling costs due to task complexity, strict quality standards, and the need for specialized expertise.
Annotation Volume and Complexity
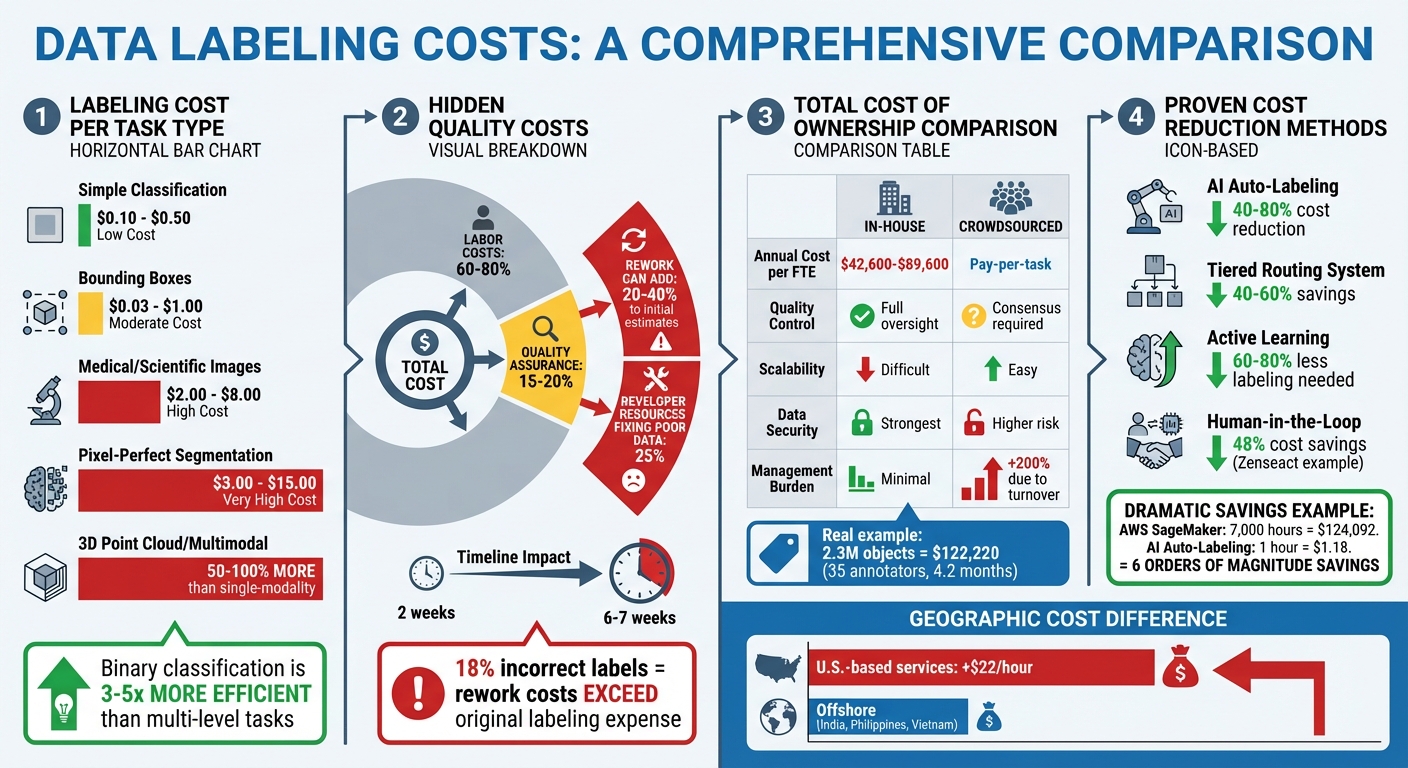
The cost of labeling varies widely depending on the task. For instance, while a simple "yes/no" classification might cost between $0.10 and $0.50 per label, more intricate tasks like pixel-perfect semantic segmentation can range from $3.00 to $15.00 per label. This stark contrast comes down to the additional time and precision required for complex annotations.
Tasks such as 3D point cloud annotation or multimodal labeling are even pricier, often costing 50%-100% more than single-modality tasks. Binary classification tasks, on the other hand, are 3 to 5 times more efficient than multi-level judgment tasks, meaning that labor and costs increase significantly as complexity rises.
Even with large-scale projects where volume discounts might seem achievable, managing a workforce of hundreds of annotators introduces logistical challenges. Coordinating such teams demands advanced project management, comprehensive training, and robust quality monitoring systems. These added layers of management often offset any savings from lower per-unit pricing, making complex tasks inherently more expensive.
Quality Control and Re-Annotation Costs
Maintaining high-quality annotations is essential but comes at a price. Quality assurance alone can account for 15%-20% of the total cost, while labor typically represents 60%-80% of overall annotation expenses.
When quality falters, rework costs can quickly spiral out of control. For example, one company reported that 25% of their developer resources were consumed fixing poor-quality data from a low-cost vendor. Another project saw its timeline stretch from 2 weeks to 6 or 7 weeks due to repeated rework cycles. As Kognic aptly noted:
The real cost of annotation isn't just what you pay your vendor - it's what you pay in engineering time, project delays, model performance, and customer satisfaction.
To ensure accuracy, many organizations implement double or even triple annotation processes, which can double labor costs. For example, a 10,000-label project initially costing $3,500 can balloon to $5,000-$5,500 with additional review layers.
Domain-Specific Annotation Requirements
Specialized datasets add another layer of expense. For instance, labeling medical data like CT or MRI scans costs 3 to 5 times more than annotating general images of similar complexity. This higher cost reflects both the time required and the expertise of licensed professionals.
Other fields, such as legal document annotation, scientific research labeling, and autonomous vehicle datasets, face similar challenges. The limited pool of qualified annotators drives up costs, as their rates often reflect their professional credentials. Medical and scientific image annotation typically ranges from $2.00 to $8.00 per label, compared to $0.03 to $1.00 for simpler tasks like bounding boxes.
Geography also plays a role in pricing. U.S.-based annotation services can cost $22.00 more per hour than services in offshore hubs like India, the Philippines, or Vietnam. For large-scale projects requiring thousands of hours, this difference can significantly affect both budgets and timelines.
Hidden Costs Beyond Per-Label Pricing
Cost Comparison: Simple vs Complex Data Labeling Tasks and Methods
When you glance at a vendor's price sheet, you're not seeing the full picture. Labeling large datasets often comes with hidden expenses that can significantly inflate overall costs. These costs frequently stem from quality issues and compliance challenges.
Costs of Rework and Quality Problems
Quality control issues can lead to skyrocketing rework expenses, often overshadowing the initial labeling costs. For instance, one company found that 25% of its developer resources were tied up fixing poor-quality data from a budget provider instead of focusing on building models. Engineers ended up acting as quality inspectors, correcting errors in annotations rather than advancing their core tasks.
What starts as a two-week project can balloon into six or seven weeks due to repeated reviews and corrections. To address these issues, organizations often need to create custom QA workflows, review pipelines, and validation scripts - tools that vendors typically handle.
Here’s a staggering example: if 18% of labels are incorrect, the cost of identifying and fixing those errors often surpasses the original labeling expense. Poor data quality doesn’t just hurt individual projects - it’s estimated to cost the U.S. economy $3.1 trillion annually. Gartner even predicts that by 2026, 60% of AI projects will fail due to quality problems.
Compliance and Legal Expenses
Quality lapses don’t just impact budgets - they can also lead to compliance risks, which come with their own hefty price tags. Industries like healthcare, finance, and automotive must adhere to strict regulations like GDPR, HIPAA, and others. Ensuring compliance requires secure environments, robust data governance, and comprehensive audit trails.
Every version of a model must be traceable back to its dataset and annotations. Building this data lineage infrastructure is costly but unavoidable for compliance. And in regulated sectors, mislabeled data doesn’t just hurt model performance - it can lead to legal liabilities and steep penalties.
On top of that, poorly managed vendor relationships can add a "relationship tax". Constant meetings, escalations, and senior leadership’s time spent managing vendor issues pull resources away from core product development. For compliance, vendors also need to provide contractual guarantees for strong data protection measures.
In-House vs. Crowdsourced Labeling Comparison
Deciding between in-house and crowdsourced labeling isn’t just about upfront costs - it’s about the total cost of ownership. Both methods come with trade-offs that influence hidden expenses.
| Factor | In-House Labeling | Crowdsourced Labeling |
|---|---|---|
| Cost Structure | High fixed costs: $42,600–$89,600 per FTE annually | Lower variable costs: pay-per-task model |
| Quality Control | Full oversight with high consistency | Relies on consensus layers; higher risk of rework |
| Scalability | Hard to scale quickly | Easily scales for large datasets |
| Data Security | Strongest; ideal for GDPR/HIPAA compliance | Higher risk; depends on vendor protocols |
| Management Burden | Minimal with direct oversight | Can increase costs by 200% due to worker turnover |
| Best Use Case | IP-sensitive, highly specialized tasks | Simple, non-sensitive, high-volume tasks |
For example, a robotics project in July 2024 by CVAT.ai revealed the complexities of in-house labeling. Annotating 2.3 million objects required 35 professional annotators and one manager over 4.2 months, costing $122,220 - and that’s not even counting software licenses or hiring overhead. Crowdsourced solutions, on the other hand, might scale faster but often require consensus models, where multiple workers annotate the same task. This approach can increase costs by at least 200% compared to high-quality first-pass processes.
The choice between these methods boils down to your project’s specific needs. In-house teams offer better control and security, but scaling can be a hurdle. Crowdsourced options provide flexibility for large volumes but often come with hidden risks and added expenses.
How to Reduce Labeling Costs for Large Datasets
After exploring the factors driving up labeling costs, let's dive into practical strategies to cut these expenses. By blending AI-powered automation with thoughtful human oversight, it’s possible to lower costs significantly while keeping - or even boosting - quality.
Using AI Models for Auto-Labeling
Foundation models like YOLO-World and Grounding DINO have made it possible to generate labels without needing human-provided seed data. These models can achieve up to 95% of human-level performance in a "zero-shot" scenario, eliminating the need for costly initial labeling rounds.
A great example comes from June 2025, when Voxel51 showcased their "Verified Auto Labeling" approach using the VOC dataset. They labeled 3.4 million objects in just over an hour on a single NVIDIA L40S GPU, with a total cost of $1.18. To put that into perspective, completing the same task with AWS SageMaker would have required nearly 7,000 hours of human effort and cost around $124,092. Dr. Jason Corso, Chief Science Officer at Voxel51, explained:
"With Verified Auto Labeling, teams can bootstrap an entire detection dataset with no human-provided seed labels and train edge-friendly detectors that nearly match fully human-supervised results. All at six orders of magnitude lower cost."
Interestingly, setting moderate confidence thresholds (between 0.2 and 0.5) often results in better downstream model performance compared to higher thresholds (e.g., 0.8–0.9), which may reduce recall. When comparing speed, YOLO-World outperforms Grounding DINO, completing dataset labeling in about 3 minutes versus 38 minutes.
Combining Automation with Human Review
A tiered routing system that combines automated labeling with human review offers a balance of speed and accuracy. Here’s how it works:
- High-confidence labels (above 0.7–0.8) are auto-accepted with occasional spot checks.
- Medium-confidence labels (0.4–0.7) are sent to human verifiers.
- Low-confidence labels (below 0.4) are fully reviewed and labeled manually.
For instance, in 2025, Zenseact, an autonomous technology company, achieved 48% cost savings by integrating their auto-labeling models into Kognic's platform for human-in-the-loop validation. This approach created a feedback loop where human corrections improved the auto-labeling model over time.
Mature systems using this method typically reduce total labeling costs by 40–60%. AI-assisted workflows can process 100,000+ images in a single day, a task that would take weeks to complete manually. In terms of labor, hours can drop by 50–70%, leading to overall project cost reductions of 30–60%.
Active Learning and Data Prioritization
Another way to cut costs is by being strategic about which data gets labeled. Active learning focuses on selecting the most "informative" samples - those where the model shows uncertainty or confusion. This approach can reduce labeling needs by 60% to 80% while maintaining or even improving accuracy.
For example, in Q4 2025, a manufacturing client working with Particula.tech implemented an active learning pipeline for defect detection. They achieved production-ready results with just 8,400 labeled images, instead of the estimated 50,000 - a reduction of 83% in labeling volume. Similarly, a financial services client using active learning reached 94% fraud detection accuracy with 6,000 labeled examples, compared to 25,000 examples required by random sampling, saving $150,000.
"Instead of labeling 10,000 random examples, you might achieve the same accuracy with 2,000 carefully chosen ones - saving 80% on labeling costs." - Particula.tech
The best results come from combining uncertainty sampling (focusing on low-confidence areas) with diversity sampling (ensuring wide coverage across the dataset). Start with a small, high-quality batch of 50–200 labeled examples to train an initial model, and then use active learning to guide further labeling efforts. Monitor performance improvements with each batch and stop labeling once gains level off to avoid wasting resources on diminishing returns.
Conclusion
Key Takeaways
Managing labeling costs effectively requires a mix of smart strategies and advanced technology. Approaches like leveraging foundation models, hybrid workflows, and active learning have shown to reduce costs by an impressive 40–80%. A tiered routing system can help strike the right balance between automation and human oversight. For instance, high-confidence labels can be automatically accepted, medium-confidence ones reviewed by humans, and low-confidence labels handled manually.
"The real cost of annotation isn't just what you pay your vendor - it's what you pay in engineering time, project delays, model performance, and customer satisfaction." – Kognic
When evaluating providers, it’s crucial to look beyond just the sticker price. Consider the total cost of ownership, which includes factors like quality assurance, rework, and delays. Running pilot projects with one or two suppliers can help you compare actual quality, speed, and pricing. This ensures the cheapest option doesn’t end up being the most expensive when hidden costs come into play.
Finding the Right Data Annotation Provider
Choosing a provider that aligns with your specific needs can make a huge difference in both cost efficiency and project success. Whether it’s ensuring HIPAA compliance for healthcare data, adhering to GDPR for European projects, or working with complex multi-modal datasets, the right partner can significantly impact your bottom line. Look for providers with trained teams that have low turnover, built-in quality assurance workflows, and the ability to scale with your growing needs.
For help finding a provider tailored to your project’s scale, complexity, and budget, the directory at Data Annotation Companies is a great starting point. It can connect you with specialists who match your requirements perfectly.
FAQs
What makes labeling costs scale faster than dataset size?
Labeling expenses tend to increase at a quicker pace than the size of the dataset. Why? Because maintaining high quality and consistency becomes significantly harder as the dataset grows. Larger datasets demand more resources for tasks like quality control, correcting errors, and ensuring accuracy throughout. These efforts become more complex and time-consuming, which naturally drives up the overall costs.
How can I estimate hidden labeling costs before I start?
When estimating the costs of labeling, it's easy to overlook some hidden expenses that can add up quickly. These include quality control, rework, and tool-related costs. Factors like the complexity of your data, the type of annotations required, and the size of your dataset can also push costs higher than expected.
Other hidden costs might involve software licenses, training staff, and management overhead. Taking the time to evaluate these elements early on can help you get a clearer picture of the total expenses and manage your budget more effectively.
When should I use in-house vs. outsourced labeling?
Choosing between in-house and outsourced data labeling comes down to factors like budget, control, and specific project requirements.
If your project involves sensitive datasets, in-house labeling might be the better choice. It offers tighter control over data security and quality. However, it does come with higher operational costs, including staffing, training, and infrastructure.
On the other hand, outsourcing is often more cost-effective and better suited for handling large datasets or quick turnarounds. That said, it’s important to account for potential hidden costs. These could include expenses related to error correction, ensuring compliance, or managing communication with external teams.
Ultimately, the decision hinges on your priorities - whether it’s maintaining security or achieving scalability.